![]()
This
Use the following menu options to navigate the SL1 user interface:
- To view a pop-out list of menu options, click the menu icon (
 ).
). - To view a page containing all the menu options, click the Advanced menu icon (
 ).
).
The following video explains the SL1 Extended Architecture:
This
What is the SL1 Extended Architecture?
SL1 Extended includes all the nodes in SL1 Distributed plus additional nodes that provide scale and new functionality.
SL1 Extended provides these new features:
- Infrastructure monitoring with the SL1 Agent
- Collectors connecting over https
- Scalable storage of performance data
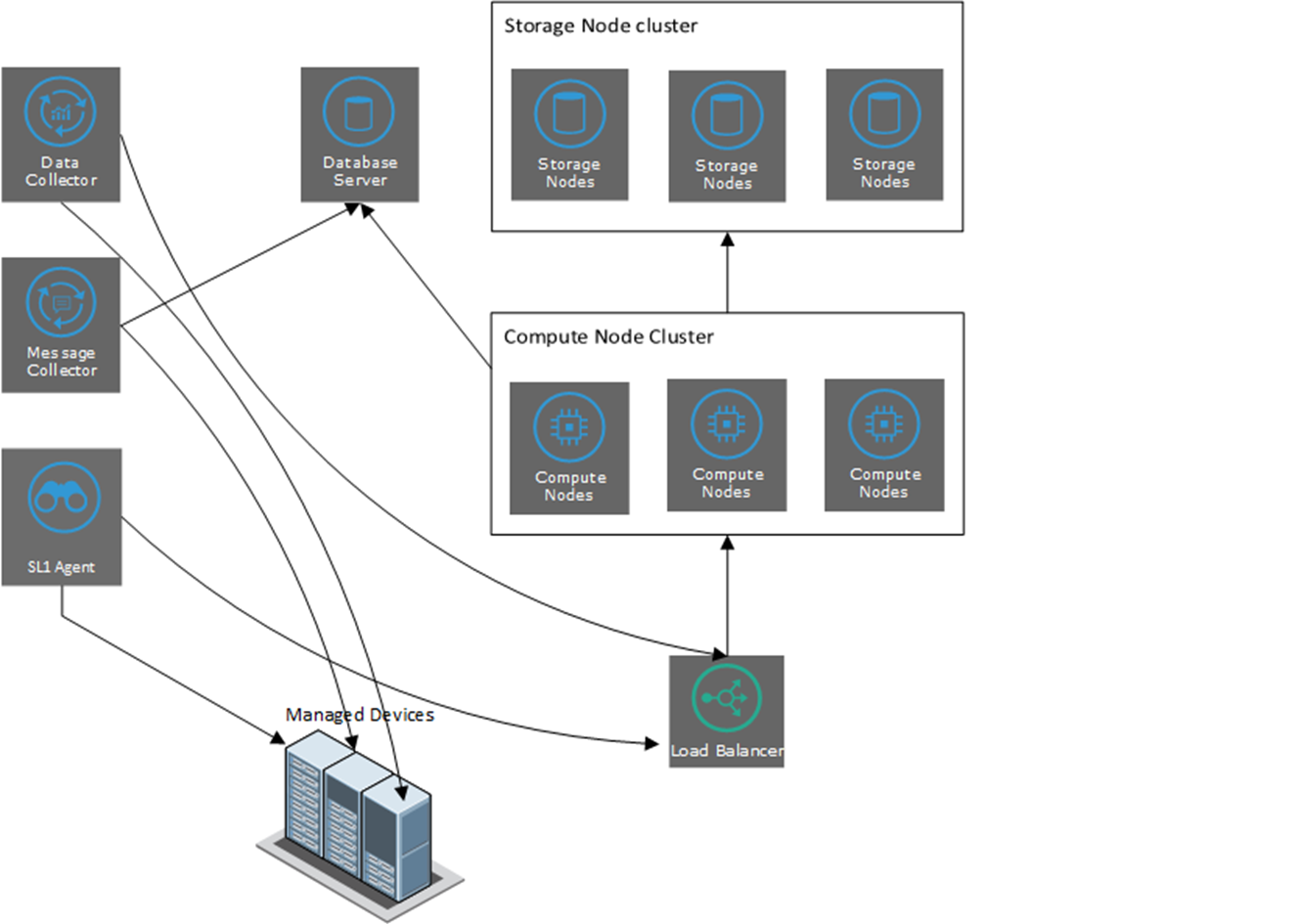
In an Extended SL1 System, the functions of SL1 are divided between multiple appliances. The smallest Extended SL1 System has:
- An Administration Portal that provides the user interface and processes requests from REST API and graphQL.
- A Database Server that stores SL1 system information and configuration data collected from managed devices.
- A Data Collector that performs data collection and message collection.
- An (optional) Message Collector that performs message collection.
- Compute Cluster (minimum of three appliances). Cluster of nodes that queues, transforms, and normalizes data collected by the SL1 Agent and the Data Collector appliance. More nodes can be added as needed.
- Load Balancer. Provides load-balancing and queues requests for the Compute Node cluster.
- Storage Cluster (minimum of three appliances). Scylla databases that store performance data collected by the SL1 Agent and the Data Collector appliance. More nodes can be added as needed.
- Management Node. Node that allows users to install and update packages on the Compute Node cluster, Storage Node cluster, and the Load Balancer.
Large SL1 systems can include multiple instances of each type of appliance. For a description of the appliance functions, see the Overview
Architecture Outline
The general architecture of a distributed system includes:
- database layer that includes a Database Server that stores SL1 configuration data and collected configuration data.
- collection layer that includes a Data Collector, a Message Collector, and the SL1 Agent.
- (optional) interface layer that includes an Administration Portal.
- Compute Node cluster (minimum of three appliances) that processes incoming data from the SL1 Agent and the Data Collector. The compute node sends configuration data to the Database Server and performance date to the Storage Node cluster.
- Load Balancer that manages requests to the Compute Node Cluster.
- Storage Node cluster (minimum of three appliances) that includes Scylla databases and stores performance data.
- Management Node that provides updates and patches for the Compute Node cluster, the Storage Node cluster and the Load Balancer.
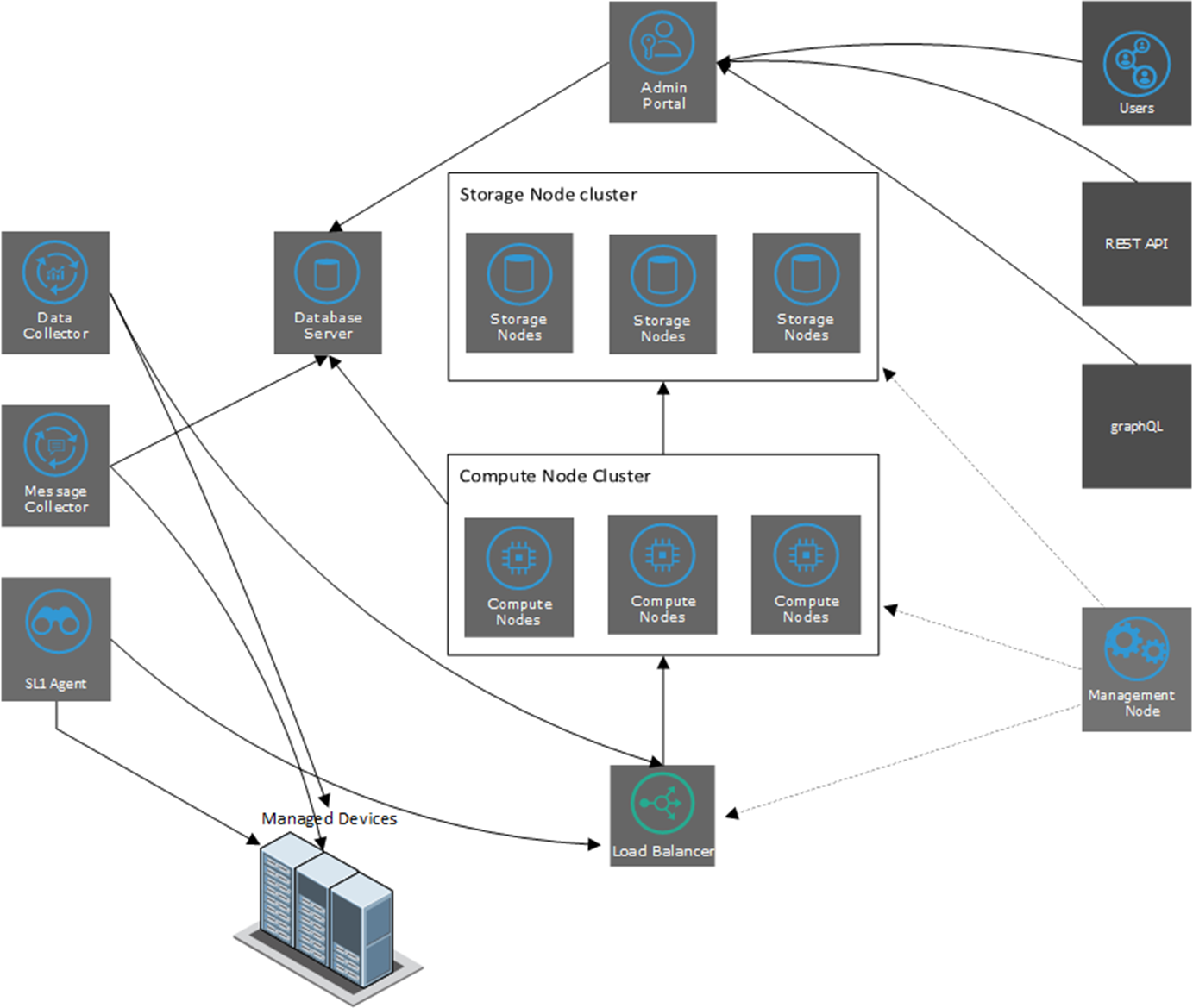
The Database Layer Configurations, Interface Layer & API Configurations, and Collector Group Configurations
For details on sizing and scaling your SL1 system to fit your workload, contact ScienceLogic Support or your Account Manager.
Database Capacity
For details on sizing and scaling the Database Server in an SL1 Extended system, see https://support.sciencelogic.com/s/system-requirements.
Message Collection
When a Data Collector is used for message collection, the Data Collector can process approximately 20 syslog or trap messages per second.
When a Message Collector is used for message collection, the Message Collector can process approximately 100 to 300 syslog or trap messages per second. The number of syslog and trap messages that can be processed is dependent on the presence and configuration of syslog and trap event policies.
For details on sizing Data Collectors and Message Collectors, see https://support.sciencelogic.com/s/system-requirements.
Interface Layer Requirements
The interface layer can include one or more Administration Portals. The Administration Portal provides access to the user interface and also generates all scheduled reports. However, in some Distributed SL1 Systems, the interface layer is optional, and the Database Server can provide all functions of the Administration Portal.
If your Distributed SL1 System meets all of the following requirements, the interface layer is optional, and your Database Server can provide all functions of the Administration Portal. If your system does not meet all of the following requirements, the interface layer is required, and you must include at least one Administration Portal in your system:
- The SL1 system will have a low number of concurrent connections to the web interface.
- The SL1 system will have a low number of simultaneously running reports.
Precise requirements for concurrent connections and simultaneously running reports vary with usage patterns and report size. Typically, a dedicated Administration Portal is recommended for a SL1 System with more than fifty concurrent connections to the web interface or more than 10 scheduled reports per hour.
For details on sizing the Administration Portal, see https://support.sciencelogic.com/s/system-requirements.
Compute Nodes
SL1 Extended includes a Compute Cluster that includes a minimum of three Compute Nodes. Each Compute Node runs Kubernetes and includes services for ingestion and transformation of data collected by the ScienceLogic Agent and the Data Collector appliance.
The SL1 Agent and Data Collectors send data to an ingestion end point on the Compute Cluster. The Compute Cluster transforms the data using specific pipelines for the different types of collected data. Transformations include enrichment with metadata, data rollup, and pattern-matching for alerting and automation.
Compute nodes also run a graph database that stores relationships for applications, infrastructure, and networks.
In larger SL1 systems, you can add additional Compute Nodes to the Compute Cluster to extended overall system capacity. For details on sizing and scaling the Compute Node cluster in an SL1 Extended system, see https://support.sciencelogic.com/s/system-requirements.
When deployed in AWS:
- SL1 Extended uses EKS (Amazon Elastic Kubernetes Service) to provide the Kubernetes control plane.
- The cluster can be configured with nodes in three distinct availability zones within the same region, allowing continuous operation in the event of an availability zone loss.
Load Balancer
The Load Balancer is a single appliance or virtual machine that provides load-balancing for the Compute Node cluster. You can include two Load Balancers, for redundancy.
For details on sizing the Load Balancer, see https://support.sciencelogic.com/s/system-requirements.
Storage Nodes
SL1 Extended includes a Storage Cluster that includes a minimum of three Storage Nodes. These Storage Nodes store performance data collected by the SL1 Agent and the Data Collector appliance. The Storage Nodes contain NoSQL databases. More Storage Nodes can be added as needed.
After the Compute Node cluster has transformed the collected data, the data is written to either the Storage Node cluster (performance data) or the Database Server (configuration data).
The NoSQL database has concepts of “rack” and “datacenter” and can use these to provide fault tolerance and latency expectations for inter-data center replication.
When deployed in AWS:
- the cluster can be configured with nodes in three distinct availability zones within the same region, allowing continuous operation in the event of an availability zone loss.
For details on sizing and scaling the Storage Node cluster in an SL1 Extended system, see https://support.sciencelogic.com/s/system-requirements.
Management Node
The Management Node runs on a single appliance or virtual machine. The Management Node allows users to install and update packages on the Compute Node cluster, Storage Node cluster, and the Load Balancer.
The SL1 Agent
In an SL1 Extended System, an SL1 agent collects data from the device on which it is installed and sends that data to a Load Balancer in front of a Compute Cluster. The Compute Cluster transforms the data and stores high-volume performance data in the Storage Cluster and other performance and configuration data in the Database Server.
In the diagram below:
- The SL1 Agent collects data from managed devices and sends the data to the Load Balancer and Compute Node cluster for processing and
- The optional Message Collector collects asynchronous traps and syslog messages and sends them to the Database Server.
- The Data Collector collects data from managed devices and sends the data to the Load Balancer and Compute Node cluster for processing and then storage.