![]()
Use the following menu options to navigate the SL1 user interface:
- To view a pop-out list of menu options, click the menu icon (
 ).
). - To view a page containing all the menu options, click the Advanced menu icon (
 ).
).
The following sections describe several options available for using the Amazon Web Services PowerPack to monitor your AWS accounts.
Configuring AWS to Report Billing Metrics
To use the "AWS: Billing Performance Percent" Dynamic Application, your AWS account must meet the following requirements:
- The user account you supplied in the AWS credential must have permission to view the us-east-1 zone.
- Your AWS account must be configured to export billing metrics to the CloudWatch service.
If your AWS account is not configured to export billing metrics to the CloudWatch service, the "AWS: Billing Performance Percent" Dynamic Application will generate the following event:
No billing metrics can be retrieved. Your AWS account is not configured to export billing metrics into CloudWatch.
To configure your AWS account to export billing metrics to the CloudWatch service, perform the following steps:
- Open a browser session and go to aws.amazon.com.
- Click and then select Billing & Cost Management. If you are not currently logged in to the AWS site, you will be prompted to log in:

- After logging in, the Billing & Cost Management Dashboard page appears. In the left navigation bar, click . The Preferences page appears:

- Select the Receive Billing Alerts checkbox.
If you enable this option, this option cannot be disabled.
- Click the button.
Filtering EC2 Instances By Tag
To discover EC2 instances and filter them by tag, you can use the "AWS Credential - Tag Filter" sample credential to enter EC2 tag keys and values.
NOTE: Filtering EC2 instance by tag will apply to all accounts discovered.
NOTE: Any EC2 instances that have already been discovered, but do not match the tag filter, will be set to "Unavailable."
To define an AWS credential:
NOTE: If you are using an SL1 system prior to version 11.1.0, the new user interface does not include the Duplicate option for sample credential(s). ScienceLogic recommends that you use the classic user interface and the Save As button to create new credentials from sample credentials. This will prevent you from overwriting the sample credential(s).
- Go to the Credentials page (Manage > Credentials).
- Locate the AWS Credential - Tag Filter sample credential, click its icon (
 ) and select Duplicate. A copy of the credential, called AWS Credential - Tag Filter copy appears.
) and select Duplicate. A copy of the credential, called AWS Credential - Tag Filter copy appears. - Click the icon () for the AWS Credential - Tag Filter copy credential and select Edit. The Edit Credential modal page appears:

- Supply values in the following fields:
- Name. Type a new name for your AWS credential.
- All Organizations. Toggle on (blue) to align the credential to all organizations, or toggle off (gray) and then select one or more specific organizations from the What organization manages this service? drop-down field to align the credential with those specific organizations.
- Timeout (ms). Keep the default value.
- URL. Enter a valid URL. This field is not used for this discovery method but must be populated with a valid URL for discovery to complete.
- HTTP Auth User. Type your AWS access key ID.
- HTTP Auth Password. Type your AWS secret access key.
- Under HTTP Headers, edit the header provided:
- Tags:<operation>#<EC2-Tag-Key>#<EC2-Tag-Value>. Type the tag, followed by its operation, tag key, or tag value. For example, if you want to filter by Tag Name, you would type the following:
Tags:equals#Name#Example
Valid operations include:
- equals
- notEquals
- contains
- notContains
You can chain together multiple filters separating them by a comma. For example:
Tags:equals#Name#Example,contains#Owner#Someone
- Click the button.
Filtering EC2 Instances by Tag in the SL1 Classic User Interface
To discover EC2 instances and filter them by tag, you can use the "AWS Credential - Tag Filter" sample credential to enter EC2 tag keys and values.
NOTE: Filtering EC2 instance by tag will apply to all accounts discovered.
NOTE: Any EC2 instances that have already been discovered, but do not match the tag filter, will be set to "Unavailable."
To define an AWS credential to discover EC2 instances and filter them by tag:
- Go to the Credential Management page (System > Manage > Credentials).
- Locate the AWS Credential - Tag Filter sample credential and click its wrench icon (
 ). The Credential Editor modal page appears:
). The Credential Editor modal page appears:

- Enter values in the following fields:
Basic Settings
- Profile Name. Type a new name for your AWS credential.
- HTTP Auth User. Type your AWS access key ID.
- HTTP Auth Password. Type your AWS secret access key.
HTTP Headers
- Edit the HTTP header provided:
- Tags:<operation>#<EC2-Tag-Key>#<EC2-Tag-Value>. Type the tag, followed by its operation, tag key, or tag value. For example, if you want to filter by Tag Name, you would type the following:
Tags:equals#Name#Example
Valid operations include:
- equals
- notEquals
- contains
- notContains
You can chain together multiple filters separating them by a comma. For example:
Tags:equals#Name#Example,contains#Owner#Someone
- Click the button, and then click .
Automatic SL1 Organization Creation
This feature is only applicable to the two discovery methods that use the Assume Role and automatically discover multiple accounts.
When multiple accounts are discovered, this feature places each account in its own SL1 organization. This feature requires an optional header in the SOAP/XML credential you will create. When this header is present, it will place each account into a new SL1 organization. When this header is not present, each account will be placed in the SL1 organization selected in the discovery session. The name of the organization can be controlled depending on what is provided in the header as follows:
- OrganizationCreation:NAME:ID. Autocreates an SL1 organization for accounts using AssumeRole. You can enter one of the following options:
- OrganizationCreation:NAME. The name of the organization will contain the name of the user.
- OrganizationCreation:ID. The name of the organization will contain the ID of the user.
- OrganizationCreation:ID:NAME. The name of the organization will contain both the ID and name of the user, in that order.
- OrganizationCreation:NAME:ID. The name of the organization will contain both the name and ID of the user, in that order.
Monitoring Consolidated Billing Accounts
Consolidated billing is an option provided by Amazon that allows multiple AWS accounts to be billed under a single account. For more information about consolidated billing, see http://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/consolidated-billing.html.
If a consolidated billing account is monitored by SL1, the billing metrics associated with that account include only the consolidated amounts, per service. If you use consolidated billing and want to collect billing metrics per-account, you must discover each account separately. To monitor only the billing metrics for an AWS account, you can create credentials that include only billing permissions.
ScienceLogic Events and AWS Alarms
In addition to SL1 collecting metrics for AWS instances, you can configure CloudWatch to send alarm information to SL1 via API. SL1 can then generate an event for each alarm.
For instructions on how configure CloudWatch and SL1 to generate events based on CloudWatch alarms, see the Configuring Inbound CloudWatch Alarms section.
Using a Proxy Server
You can use a proxy server with the Manual Discovery and the Automated Discovery Using AssumeRole with a Single IAM Key from the AWS Master Account discovery methods.
To use a proxy server in both cases, you must fill in the proxy settings in the SOAP/XML credential.
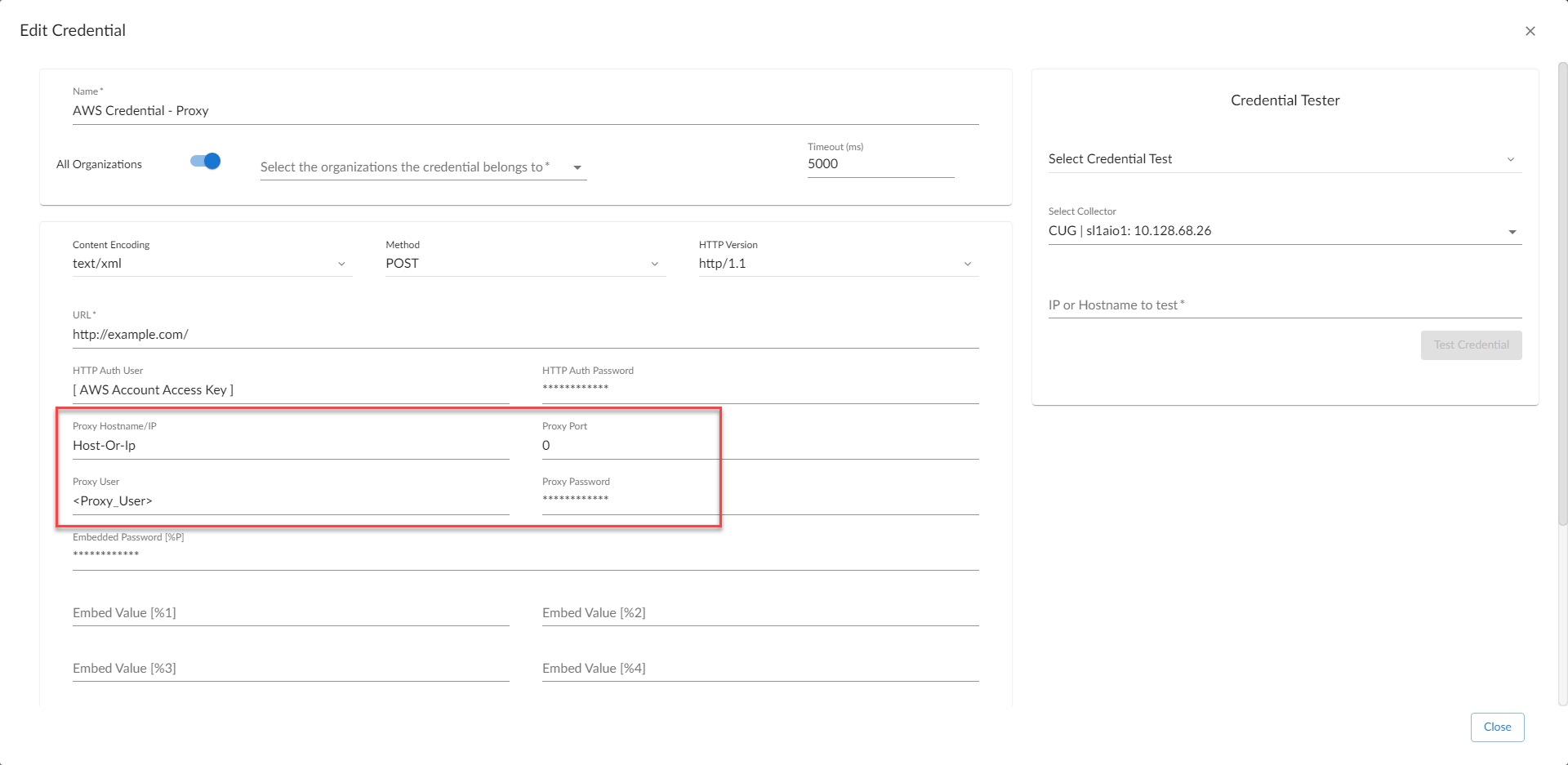
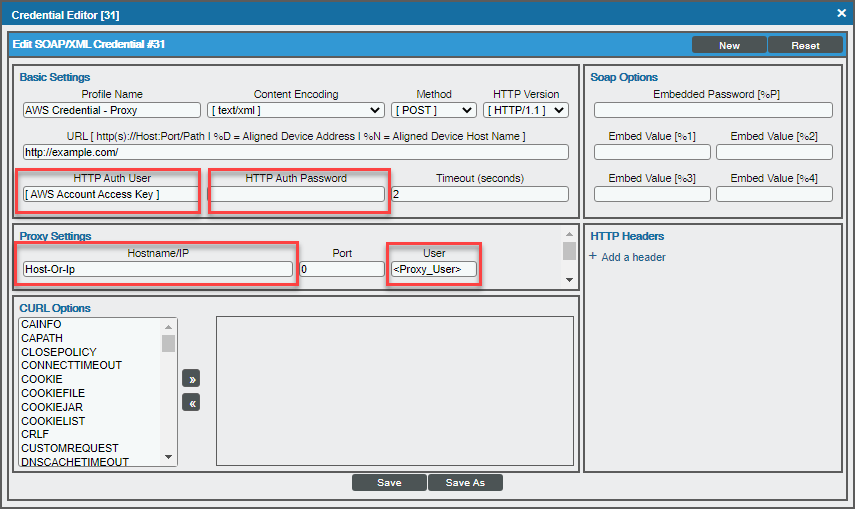
For the Automated Discovery Using AssumeRole with a Single IAM Key from the AWS Master Account discovery method, if the proxy does not support ping passthrough you will also need to follow the steps in the Automated Discovery Using AssumeRole with a Single IAM Key from the AWS Master Account section without ping support.
Configuring "AWS: Lambda Service Discovery"
By default, the "AWS: Lambda Service Discovery" Dynamic Application is configured to discover only regular Lambda functions, not replica functions. If you want to discover both regular and replica Lambda functions, then you must configure the "AWS: Lambda Service Discovery" Dynamic Application to do so prior to discovering your Lambda service.
To configure the "AWS: Lambda Service Discovery" Dynamic Application to discover both regular and replica Lambda functions:
- Go to the Dynamic Applications Manager page (System > Manage > Applications).
- Locate the "AWS: Lambda Service Discovery" Dynamic Application and click its wrench icon (). The Dynamic Applications Properties Editor page appears.
- In the Operational State field, select Disabled, and then click . This disables the Dynamic Application from collecting data.

- Click the tab. The Dynamic Applications Snippet Editor & Registry page appears.
- In the Snippet Registry pane, click the wrench icon () for the "aws_lambda_service_discovery" snippet.
- In the Active State field, select Disabled, and then click . This disables the "aws_lambda_service_discovery" snippet.

- In the Snippet Registry pane, click the wrench icon () for the "aws_lambda_service_discovery_show_replicas" snippet.
- In the Active State field, select Enabled, and then click . This enables the "aws_lambda_service_discovery_show_replicas" snippet.
- Click the tab. The Dynamic Applications | Collections Objects page appears.
- Click the wrench icon () for the first Collection Object listed in the Collection Object Registry pane, select aws_lambda_service_discovery_show_replicas in the Snippet field for that Collection Object, and then click .

- Repeat step 10 for all of the remaining Collection Objects listed in the Collection Object Registry pane.
- Click the tab.
- In the Operational State field, select Enabled, and then click . This re-enables data collection for the Dynamic Application.
If you configure the "AWS: Lambda Service Discovery" Dynamic Application to discover both regular and replica Lambda functions, then when you run discovery, the Dynamic Applications in the Amazon Web Services PowerPack will create parent/child relationships between replica Lambda functions and their corresponding master Lambda functions. In this scenario, the Device View and other device component maps will display the relationship in this order: Lambda Function Service > Lambda Replica Function > Master Lambda Function. The replica appears as the parent to the master Lambda function because the replica could be in the same or a different region than the master Lambda function.
Configuring "AWS: Lambda Function Qualified Discovery"
By default, the "AWS: Lambda Function Qualified Discovery" Dynamic Application is configured to discover and model all Lambda alias components. An alias is a qualifier inside an AWS Lambda function that enables the user to control which versions of the Lambda function are executable—for instance, a production version and a test version.
When the "AWS: Lambda Function Qualified Discovery" Dynamic Application is configured to discover alias components, SL1 collects data only for the Lambda function versions specified in the alias.
Depending on your needs, you can optionally configure the Dynamic Application to instead do one of the following:
- Discover and model all Lambda version components. If you select this configuration, SL1 collects data for all existing versions of the Lambda function.
- Discover and model only Lambda version components with AWS configurations filtered by a trigger. If you select this configuration, SL1 collects data only for versions of the Lambda function that have triggers or are specified in an alias.
If you have configured the "AWS: Lambda Service Discovery" Dynamic Application to discover both regular and replica Lambda functions and you want SL1 to create dynamic component map relationships between replica Lambda functions and their parent Lambda function versions, you must follow these instructions to configure the "AWS: Lambda Function Qualified Discovery" Dynamic Application to discover and model all Lambda version components.
To configure the "AWS: Lambda Function Qualified Discovery" Dynamic Application:
- Go to the Dynamic Applications Manager page (System > Manage > Applications).
- Locate the "AWS: Lambda Function Qualified Discovery" Dynamic Application and click its wrench icon (
 ). The Dynamic Applications Properties Editor page appears.
). The Dynamic Applications Properties Editor page appears.
- In the Operational State field, select Disabled, and then click . This disables the Dynamic Application from collecting data.

- Click the tab. The Dynamic Applications Snippet Editor & Registry page appears. The Snippet Registry pane includes the following snippets:
- aws_lambda_function_aliases_discovery. When this snippet is enabled, the Dynamic Application discovers all Lambda alias components.
- aws_lambda_function_all_versions_discovery. When this snippet is enabled, the Dynamic Application discovers all Lambda version components.
- aws_lambda_function_versions_by_triggers_discovery. When this snippet is enabled, the Dynamic Application discovers Lambda version components with AWS configurations containing a trigger or those with an alias.
- One at a time, click the wrench icon () for each of the snippets, select Enabled or Disabled in the Active State field, and then click to enable the appropriate snippet and disable the others.

You can enable only one of these snippets at a time.
- Click the tab. The Dynamic Applications | Collections Objects page appears.
- Click the wrench icon () for the first Collection Object listed in the Collection Object Registry pane, select the snippet you enabled in step 5 in the Snippet field for that Collection Object, and then click .

- Repeat step 7 for all of the remaining Collection Objects listed in the Collection Object Registry pane.
- Click the tab.
- In the Operational State field, select Enabled, and then click . This re-enables data collection for the Dynamic Application. The next time discovery is run, new component devices might be discovered and some previously discovered components might become unavailable, depending on how you configured the Dynamic Application.
If you configure the "AWS: Lambda Function Qualified Discovery" Dynamic Application to discover Lambda alias or version components and your AWS service includes an API Gateway that triggers a Lambda Function, then the Dynamic Applications in the Amazon Web Services PowerPack will create a device relationship between that Lambda Function and its corresponding Lambda alias or version component device.
Configuring AWS Integration with Docker
If you have discovered EC2-backed ECS clusters using the Amazon Web Services PowerPack, you can optionally use the Docker PowerPack to collect container information in addition to what the AWS API provides for the ECS service.
NOTE: This integration does not work with Fargate-backed ECS clusters.
To configure this integration, cURL version 7.40 or later must be installed on the ECS AMI image. For example, the 2018.03 ECS AMI image is compatible is compatible because it includes cURL 7.43.1.
Additionally, you must install the most recent version of the Docker PowerPack on your SL1 System and run a discovery session using an SSH credential that will work on the EC2 host(s). This discovery session will discover the EC2 instances that comprise the ECS cluster and align the Docker host Dynamic Applications with those EC2 instances. Optionally, you can merge the EC2 host with the Docker host if you so choose.
NOTE: For more information about the Docker PowerPack, including instructions about creating the SSH credential and running discovery, see
NOTE: ScienceLogic does not recommend enabling and securing the Docker HTTP API when aligning EC2 instances with Docker hosts. Doing so requires you to complete manual steps on each EC2 host. Furthermore, if you use this method and then merge the EC2 host with the Docker host, data collection will fail for all containers that are children of the merged host.
Configuring AWS Integration with Kubernetes
If you are using the AWS EKS service you can optionally use the Kubernetes PowerPack to provide visibility into your Kubernetes worker nodes and their associated workloads.
To use the Kubernetes PowerPack with the Amazon Web Services PowerPack, you must have the following versions of these PowerPacks installed:
- Amazon Web Services version 118 or later
- Kubernetes version 104 or later
If you are using AWS EKS but do not want to use this feature, then it is recommended to disable the "AWS EKS Cluster Virtual Discovery" Dynamic Application. To do this:
- Go to the Dynamic Applications Manager page (System > Manage > Dynamic Applications).
- Search for "AWS EKS" in the Dynamic Application Name column.
- Click on the wrench icon () for the "AWS EKS Cluster Virtual Device Discovery" Dynamic Application and set the Operational State dropdown to Disabled.
- Click the button.
Using the Kubernetes PowerPack is completely automated on SL1. If the proper credentials have been assigned on AWS and the AWS EKS Cluster, then SL1 will automatically discover the Kubernetes worker nodes and the associated workloads. The following additional components will be automatically created:
- A new DCM tree root device to represent the Kubernetes cluster. This will be a virtual device of the type "Kubernetes Cluster".
- A child component of the cluster will be created for each worker node in the cluster. This will be a component device of the type "Kubernetes Node".
- A child component of the cluster will be created that represents the Namespaces. This will be a component device of the type "Kubernetes Namespace Folder".
- A child component of the Namespace Folder will be created for each Namespace discovered. This will be a component device of the type "Kubernetes Namespace".
- A child component of the Namespace will be created for each controller discovered as follows:
- Kubernetes Daemon Set
- Kubernetes Deployment
- Kubernetes Job
- Kubernetes Cronjob
- Kubernetes Replication Controller
- Kubernetes Replication Set
- Kubernetes Stateful Set
NOTE: At most only a single component is created to represent a controller. If a deployment and replica set exists, SL1 models only the deployment and replica set info as provided by the deployment component.
- A child component of the cluster will be created for each ingress defined. This will be a component device of the type "Kubernetes: Ingress".
For SL1 to automatically discovery the EKS cluster, you must perform the following steps:
NOTE: When logging into the Kubernetes cluster, ensure that the AWS credentials that kubectl is using are already authorized for your cluster. The IAM user that created the cluster has these permissions by default.
- Enable the Prometheus Metrics Server. AWS EKS does not have the metrics server enabled by default. This is highly recommended as it will provide CPU and memory utilization metrics for both the worker nodes as well as the pods.
NOTE: SL1 automatically aggregates the CPU and memory utilization for pods and presents data at the controller level.
- Define the cluster role needed by SL1 so that it can access the necessary APIs. This is done on the EKS Cluster.
- Define the ClusterRoleBinding. This is done on the EKS Cluster.
- Map the IAM user or role to the RBAC role and groups using the aws-auth ConfigMap. This is done on the EKS Cluster.
Enabling the Prometheus Metrics Server
The Prometheus Metrics Server is required to provide CPU and memory utilization for pods and for nodes. The metrics server can be easily installed on Kubernetes clusters with the following:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
To verify that the server is running, execute the command:
kubectl get deployment metrics-server -n kube-system
The following output will show that the metrics server is running:
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 1/1 1 14h
Define the Cluster Role
The cluster role defines the minimum permissions that SL1 needs to monitor the Kubernetes cluster. ClusterRole is used as it provides access to all namespaces. Since SL1 is directly monitoring the Kubernetes cluster via the Kuberneties API, this role's permissions need to be defined on the cluster itself.
To define the cluster role in Kubernetes:
- Log in to the EKS cluster with the same user or role that created the cluster.
- Create a new file called SL1_cluster_role.yaml and cut and paste the following text into that file:
YAML requires specific spacing. Please double-check the spacing after cutting-and-pasting code into YAML files.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: eks-readonly-clusterrole
rules:
- apiGroups:
- ""
resources:
- nodes
- namespaces
- pods
- replicationscontrollers
- events
- persistentvolumes
- persistentvolumeclaims
- componentstatuses
- services
verbs:
- get
- list
- watch
- apiGroups:
- apps
resources:
- deployments
- daemonsets
- statefulsets
- replicasets
verbs:
- get
- list
- watch
- apiGroups:
- batch
resources:
- jobs
- cronjobs
verbs:
- get
- list
- watch
- apiGroups:
- metrics.k8s.io
resources:
- nodes
- pods
verbs:
- get
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- get
- list
- watch
The above file defines the minimum read-only permissions needed for SL1 to monitor Kubernetes.
- Once the file is defined, execute the following command to apply the file:
kubectl apply -f cluster_role.yaml
Define the ClusterRoleBinding
Once the role is defined, it must be bound to users, groups, or services. This is done by defining a ClusterRoleBinding:
- Log in to the EKS cluster with the same user or role that created the cluster.
- Create a new file called SL1_ClusterRoleBinding.yaml and cut and paste the following text into that file:
YAML requires specific spacing. Please double-check the spacing after cutting-and-pasting code into YAML files.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: eks-cluster-role-binding
subjects:
- kind: User
name: Sciencelogic-Monitor
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: eks-readonly-clusterrole
apiGroup: rbac.authorization.k8s.io
- Once the file is created, apply the ClusterRoleBinding by executing the following command:
kubectl apply -f SL1_ClusterRoleBinding.yaml
NOTE: Under subjects, "name: Sciencelogic-Monitor" defines the Kubernetes user and it must match the username field in the config map shown below.
NOTE: Under roleRef, "name: eks-readonly-clusterrole" must match the name defined in the cluster role.
Map the IAM User or Role to the Kubernetes RBAC Role
After defining the ClusterRoleBinding, you must map the AWS credentials that SL1 is using to the username created above in the SL1_ClusterRoleBinding.yaml file. To do this, perform the following steps:
- Enter the kubectl edit -n kube-system configmap/aws-auth command. This will bring up the configmap. How the configmap is updated depends on what type of IAM was used to discover SL1.
NOTE: If the configmap/aws-auth does not exist, follow the procedures defined in https://docs.aws.amazon.com/eks/latest/userguide/add-user-role.html
Example 1
If SL1 has discovered your AWS organization using assume role, add the following text to the mapRoles: section in the configmap:
YAML requires specific spacing. Please double-check the spacing after cutting-and-pasting code into YAML files.
- groups:
- eks-cluster-role-binding
rolearn:arn:aws:iam::<Account number that hosts the Kubernetes cluster>:role/Sciencelogic-Monitor
username: Sciencelogic-Monitor
NOTE: If mapRoles does not exist, then you can add the mapRoles section to the configmap.
The text should appear in the configmap as the highlighted text below:
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an emty file will abort the edit. If an error occurs while saving, this fiel will be
# reopened with the relevant failures
#
apiVersion: v1
data:
mapRoles: |
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws-us-gov:iam::<account number>:role/eksctl-eks-cluster-testfriday-nod-NodeInstanceRole-6VCMS669U9NA
username: system:node:{{EC2PrivateDNSName}}
- groups:
- eks-cluster-role-binding
rolearn: arn:aws:iam::<account number>:role/Sciencelogic-Monitor
username: Sciencelogic-Monitor
kind: ConfigMap
metadata:
creationTimestamp: "2021-07-30T20:43:55Z"
name: aws-auth
namespace: kube-system
resourceVersion: "173718"
selfLink: /api/v1/namespaces/kube-system/configmaps/aws-auth
uid: d1bcdafd-fc40-44e6-96d4-9a079b407d06
Example 2
If SL1 has been discovered with a single IAM key for the account, add the following text to the mapUsers: section of the configmap:
YAML requires specific spacing. Please double-check the spacing after cutting-and-pasting code into YAML files.
- groups:
- eks-cluster-role-binding
userarn:arn:aws:iam::<Account number that hosts the Kubernetes cluster>:user/<Name of the user associated with the IAM key
username: Sciencelogic-Monitor
The text should appear in the configmap as the highlighted text below:
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an emty file will abort the edit. If an error occurs while saving, this fiel will be
# reopened with the relevant failures
#
apiVersion: v1
data:
mapRoles: |
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws-us-gov:iam::<account number>:role/eksctl-eks-cluster-testfriday-nod-NodeInstanceRole-6VCMS669U9NA
username: system:node:{{EC2PrivateDNSName}}
mapUsers: |
- groups:
- eks-cluster-role-binding
userarn: arn:aws:iam::<account number>:user/<username>
username: Sciencelogic-Monitor
kind: ConfigMap
metadata:
creationTimestamp: "2021-07-30T20:43:55Z"
name: aws-auth
namespace: kube-system
resourceVersion: "173718"
selfLink: /api/v1/namespaces/kube-system/configmaps/aws-auth
uid: d1bcdafd-fc40-44e6-96d4-9a079b407d06
NOTE: In userarn: arn:aws:iam::<account number>:user/<username>, the username is the userarn that SL1 is using to monitor the Kubernetes cluster.
NOTE: Under mapUsers, the username: is the name used in the ClusterRoleBinding.
Amazon API Throttling Events
By default, SL1 will use the Collector Group aligned with the root AWS virtual device to retrieve data from AWS devices and services.
If SL1 must collect data from a large set of AWS devices and services, SL1 might generate Notify events with a message ending in the text "Retry #1-10 Sleeping: ... seconds". SL1 generates these events when the Amazon API throttles collection in response to a large number of requests to the API. Even though SL1 is generating Notify "Retry" events, SL1 is still collecting data from AWS. This issue commonly occurs when a specific Amazon data center edge is close to capacity.
If SL1 generates the Minor event "Collection missed on <device> on 5 minute poll", this indicates that SL1 was unable to retrieve that specific datum from the Amazon cloud during the most recent five-minute polling cycle. If you frequently see the "Collection missed" event across your cloud, you must contact Amazon support to whitelist the IP address of your Data Collector. This will prevent further throttling from occurring.
Support for AWS China Regions
Currently, the only method of discovery for AWS China Regions is the Manual Discovery method. In this case, the Embed Value %1 field in the SOAP/XML credential must contain the specific Chinese region to be monitored.
Support for AWS GovCloud Regions
AWS GovCloud Regions can be discovered using all discovery methods as defined below:
- For an individual account using the Manual Discovery method, type the name of the AWS GovCloud region in the Embed Value %1 field in the SOAP/XML credential.
- For those using one of the discovery methods with AssumeRole, enter one of the following URLs in the URL field of the SOAP/XML credential to specify the specific government region:
- https://organizations.us-gov-west-1.amazonaws.com
- https://organizations.us-gov-east-1.amazonaws.com
NOTE: All examples shown are for commercial AWS accounts. When AWS Gov is being monitored, the JSON data that refers to ARN will need to be modified from "aws" to "aws-us-gov". For example: Resource": "arn:aws:iam::<account number>:role/Sciencelogic-Monitor would need to be Resource": "arn:aws:iam-us-gov::<account number>:role/Sciencelogic-Monitor
Migrating from Using an IAM Key Per Account to Using AssumeRole
SL1 supports the ability to migrate accounts that were originally discovered using an IAM key per account to start using AssumeRole. To upgrade, perform the following steps:
- Run steps 1-4 in the Automated Discovery when the Data Collector Runs as an EC2 Instance section
or
Run steps 1-3 of the Automated Discovery Using AssumeRole with a Single IAM Key from the AWS Master Account section. - Next you must disable collection for every account that is being migrated. To do this, go to the Device Components page (Devices > Device Components, or Registry > Devices > Device Components in the SL1 classic user interface) and enter "AWS | Service" in the Device Class | Sub-class column.
- Select the checkbox for each account being migrated.
- In the Select Action menu, select _Disabled under Change Collection State. Click .
Failing to disable collection for accounts that will be migrated will result in a loss of data.
If you have a large number of accounts that will be migrated, it is recommended to start with a single account to ensure that all settings migrate correctly. To limit the accounts that are migrated, put only a single account in the ec2-collector policy so SL1 will assume the role for that single account. Once you have ensured that the one account has been migrated successfully, you can add the other accounts back into the ec2-collector policy.
NOTE: If you had previously changed the account name in SL1, the upgrade process will overwrite any changes made to the name of the account component.
NOTE: If you had previously placed your accounts into different SL1 organizations, these organization names will be preserved upon upgrading. However, if you add the headers for SL1 organizations to your SOAP/XML credential, then the SL1 organizations will be set according to the SOAP header.
Once discovery has completed successfully, the Dynamic Applications aligned to the root device and the component device will display the new credential used in the discovery process, while the Dynamic Applications for the child device(s) of the account device will still display the old credential. While you cannot delete the credentials, you can remove the IAM keys from those credentials as they are no longer being used by the Dynamic Applications.