Available Steps¶
Syntax¶
Low-Code¶
The low_code Syntax is a YAML configuration format for specifying your collections. You explicitly provide the steps you want to run, in the order you need them to be executed. There are multiple versions of the low_code Syntax.
Framework Name |
|
All versions support specifying configuration. The configuration will be
all sub-elements under the step. For example, if you had a step cool_step
and wanted to specify two key values, you would provide the following:
low_code:
id: eastwood1
version: 2
steps:
- cool_step:
key1: value1
key2: value2
Note
Notice that, in the example above, key1 and key2 are indented
one level beyond cool_step. Setting them at the same indentation
level as cool_step, as shown below, will result in an error.
low_code:
id: eastwood1
version: 2
steps:
- cool_step:
key1: value1 # key1 is not properly indented
key2: value2 # key2 is not properly indented
To provide a list in YAML you will need to utilize the - symbol. For example,
if you had a step cool_step and wanted to specify a list
of two elements, you would provide the following:
low_code:
id: eastwood1
version: 2
steps:
- cool_step:
- key1
- key2
Version 2¶
Version 2 of the low_code Syntax provides more flexibility when defining the order of step execution. This version can utilize multiple versions of Requestors (if supported) and allows for steps to run before a Requestor executes.
Format¶
low_code:
id: eastwood1
version: 2
steps:
- static_value: '{"key": "value"}'
- json
- simple_key: "key"
id: Identification for the request.
Note
If this value is not specified, the Snippet Framework will automatically create one. This allows for easier tracking when debugging when an ID is not required for the collection.
version: Specify the version of the low_code Syntax.
steps: Order of the steps for the Snippet Framework to execute.
Version 1¶
Version 1 was the original low_code syntax. It allowed for a single Requestor and any number of processors. It lacks support for multiple Requestors so it is not preferred.
Format¶
low_code:
id: my_request
network:
static_value: '{"key": "value"}'
processing:
- json
- simple_key: "key"
id: Identification for the request.
Note
If this value is not specified, the Snippet Framework will automatically create one. This allows for easier tracking when debugging when an ID is not required for the collection.
version: Specify the version of the low_code Syntax. If not provided, it will default to 1.
network: Section for the data requester step.
processing: Section for listing the steps required to transform your data to the desired output for Skylar One to store.
Requestors¶
SSH¶
The Secure Shell (SSH) Data Requester allows users to communicate with remote devices through SSH-request functionality. Users can access a command-line shell on a remote, or server, through the network’s protocol.
Through SSH’s strong encryption and authentication, commands can be executed securely. The protocol supports two methods of authentication. A user can use their username and password, or an SSH key. An SSH key is a specific access credential that performs the same functionality as the first method, but with stronger reliability.
For the first authentication method, use the Username and Password fields. For SSH key authentication, use the Username and Private Key fields.
Step details include:
Step Name |
|
Package |
silo.ssh_lc |
Supported Credentials |
SSH/Key Credential |
Supported Fields of Credential |
|
Configuration of arguments¶
There are two types of arguments that can be configured to return data for a collection object.
This includes:
Argument |
Type |
Default |
Description |
|---|---|---|---|
command |
string |
None |
Required. This argument sets the command for execution. |
standard_stream |
string |
stdout |
Optional. This argument sets the standard streams. The
possible values are:
- stdout - Standard output, stream to which the command
writes its output data.
- stderr - Standard error, another output stream to
output error messages.
|
Below is an example of a command argument used to retrieve data about the CPU architecture of a Unix system.
lscpu
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- ssh:
command: lscpu
The output of this example step would look similar to:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 45
Model name: Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz
Stepping: 2
CPU MHz: 2299.998
BogoMIPS: 4599.99
Hypervisor vendor: VMware
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 25600K
NUMA node0 CPU(s): 0-3
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss ht syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology tsc_reliable nonstop_tsc eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx hypervisor lahf_lm ssbd ibrs ibpb stibp tsc_adjust arat md_clear spec_ctrl intel_stibp flush_l1d arch_capabilities
Static Value¶
The Static Value Data Requester is used to mock network responses from a device for testing purposes or when a step needs a static name.
Step details:
Framework Name |
|
Supported Credentials |
N/A |
Example of use¶
If we wanted to mock:
"Apple1,Ball1,Apple2,Ball2"
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- static_value: "Apple1,Ball1,Apple2,Ball2"
- firstComponentExecution
- secondComponentExecution
Processors¶
Data Parsers¶
CSV¶
The CSV Data Parser converts a string into the format requested by the Args.
Step details:
Framework Name |
|
Parameters |
All the arguments inside:
|
Reference |
Example Usage¶
If the incoming data to the step is:
"A1,B1,C1
A2,B2,C2 A3,B3,C3 “
If we wanted to provide these input parameters:
"type": "dict"
The output of this step will be:
[
["A1", "B1", "C1"],
["A2", "B2", "C2"],
["A3", "B3", "C3"],
]
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- csv:
type: dict
If the incoming data to the step is:
"First,Last,Email
Jonny,Lask,jl@silo.com Bobby,Sart,bs@silo.com Karen,Sift,ks@silo.com “
If we wanted to provide these input parameters:
"type": "dict"
The output of this step will be:
[
{"First": "Jonny", "Last": "Lask", "Email": "jl@silo.com"},
{"First": "Bobby", "Last": "Sart", "Email": "bs@silo.com"},
{"First": "Karen", "Last": "Sift", "Email": "ks@silo.com"},
]
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- csv:
type: dict
If the incoming data to the step is:
"booker12,9012,Rachel,Booker"
If we wanted to provide these input parameters:
"fieldnames": ["Username", "Identifier", "First name", "Last name"]
"type": "dict"
The output of this step will be:
[
{'Username': 'booker12', 'Identifier': '9012', 'First name': 'Rachel', 'Last name': 'Booker' }
]
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- csv:
fieldnames:
- Username
- Identifier
- First name
- Last name
type: dict
jc¶
JC is a third-party library that enables easy conversion of text output to python primitives. While this is primarily used for *nix parsing, it includes other notable parsers such as xml, ini, and yaml to name a few. The entire list of supported formats and their respective outputs can be found on their github.
Note
The Snippet Framework does not support streaming parsers (parsers that end in _s). These will not appear in the list of available parsers.
Step details:
Framework Name |
|
Parameters |
|
Reference |
Supplying additional key / value pairs within the action argument will
pass-through this information to the parser. For example, if you
needed to run the parser example_parser and it took the option
sample_argument, you would use the following:
jc:
parser_name: example_parser
sample_argument: value_pass_through
If no additional parameters need to be supplied, you can specify the parser_name as the action argument to reduce typing.
jc: example_parser
There are current 125 parsers available in the installed version of jc v1.23.0. The list of available parsers are as follows:
acpi, airport, arp, asciitable, asciitable_m, blkid, cbt, cef, chage, cksum, clf, crontab, crontab_u, csv, date, datetime_iso, df, dig, dir, dmidecode, dpkg_l, du, email_address, env, file, findmnt, finger, free, fstab, git_log, git_ls_remote, gpg, group, gshadow, hash, hashsum, hciconfig, history, hosts, id, ifconfig, ini, ini_dup, iostat, ip_address, iptables, iw_scan, iwconfig, jar_manifest, jobs, jwt, kv, last, ls, lsblk, lsmod, lsof, lspci, lsusb, m3u, mdadm, mount, mpstat, netstat, nmcli, ntpq, openvpn, os_prober, passwd, pci_ids, pgpass, pidstat, ping, pip_list, pip_show, plist, postconf, proc, ps, route, rpm_qi, rsync, semver, sfdisk, shadow, ss, ssh_conf, sshd_conf, stat, sysctl, syslog, syslog_bsd, systemctl, systemctl_lj, systemctl_ls, systemctl_luf, systeminfo, time, timedatectl, timestamp, toml, top, tracepath, traceroute, udevadm, ufw, ufw_appinfo, uname, update_alt_gs, update_alt_q, upower, uptime, url, ver, vmstat, w, wc, who, x509_cert, xml, xrandr, yaml, zipinfo, zpool_iostat, zpool_status
JSON¶
The JSON Data Parser converts a JSON string into a python dictionary.
Framework Name |
|
Example Usage¶
If the incoming data to the step is:
'{
"project": "low_code", "tickets": {"t123": "selector work",
"t321": "parser work"}, "name": "Josh", "teams": '["rebel", "sprinteastwood"]
}'
The output of this step will be:
{
"name": "Josh",
"project": "low_code",
"teams": ["rebel", "sprinteastwood"],
"tickets": {"t123": "selector work", "t321": "parser work",},
}
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- json
Parse Ifconfig¶
The Parse Ifconfig converts the response of the ifconfig command into a
dictionary by using the ifconfig-parser module. The output dictionary
contains Interface Configuration data, where the keys are the interface names.
Step details:
Step |
|
Incoming data type |
string or list of strings |
Return data type |
dictionary |
Below is an example of a Parse Ifconfig step.
Incoming data to step:
ens160 Link encap:Ethernet HWaddr 00:50:56:85:73:0d inet addr:10.2.10.45 Bcast:10.2.10.255 Mask:255.255.255.0 inet6 addr: fe80::916b:4b90:721d:a731/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:5212713 errors:0 dropped:25051 overruns:0 frame:0 TX packets:1291444 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:2300868310 (2.3 GB) TX bytes:266603934 (266.6 MB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:28287 errors:0 dropped:0 overruns:0 frame:0 TX packets:28287 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1 RX bytes:8793361 (8.7 MB) TX bytes:8793361 (8.7 MB)
Output:
{ "ens160": { "name": "ens160", "type": "Ethernet", "mac_addr": "00:50:56:85:73:0d", "ipv4_addr": "10.2.10.45", "ipv4_bcast": "10.2.10.255", "ipv4_mask": "255.255.255.0", "ipv6_addr": "fe80::916b:4b90:721d:a731", "ipv6_mask": "64", "ipv6_scope": "Link", "state": "UP BROADCAST RUNNING MULTICAST", "mtu": "1500", "metric": "1", "rx_packets": "5212713", "rx_errors": "0", "rx_dropped": "25051", "rx_overruns": "0", "rx_frame": "0", "tx_packets": "1291444", "tx_errors": "0", "tx_dropped": "0", "tx_overruns": "0", "tx_carrier": "0", "rx_bytes": "2300868310", "tx_bytes": "266603934", "tx_collisions": "0", }, "lo": { "name": "lo", "type": "Local Loopback", "mac_addr": None, "ipv4_addr": "127.0.0.1", "ipv4_bcast": None, "ipv4_mask": "255.0.0.0", "ipv6_addr": "::1", "ipv6_mask": "128", "ipv6_scope": "Host", "state": "UP LOOPBACK RUNNING", "mtu": "65536", "metric": "1", "rx_packets": "28287", "rx_errors": "0", "rx_dropped": "0", "rx_overruns": "0", "rx_frame": "0", "tx_packets": "28287", "tx_errors": "0", "tx_dropped": "0", "tx_overruns": "0", "tx_carrier": "0", "rx_bytes": "8793361", "tx_bytes": "8793361", "tx_collisions": "0", }, }The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_ifconfig
Parse Line¶
The Parse Line converts a simple Unix command output into an addressable data structure; usually a dictionary.
Step details:
Step |
|
Incoming data type |
string |
Return data type |
iterable |
Configuration of arguments¶
There are two types of arguments that can be configured to return data for a collection object. However, these arguments are optional; meaning, if unprovided, the step will return the same input value.
This includes:
Argument |
Type |
Default |
Description |
|---|---|---|---|
split_type |
string |
“” |
Optional. This argument determines the split type.
For this particular step, the only valid option is
colon. |
key |
string |
“” |
Optional. This argument sets a key in the final
result. The other possible value is
from_output. |
If you only provide the “key” argument with a given value, a dictionary with one item will be returned. The key of this dictionary is what you provide in the “key” argument, and the value is the input of the step.
If you provide the “split_type” argument with the value colon and the
“key” argument with the value from_output, a dictionary will be returned
where each line of the input to the step is an element. In this dictionary,
the keys and values appear due to the data being separated by the “:”
character.
The values of these two arguments must match to get this behavior. If any other value for split_type and key is provided, an empty dictionary will be the returned result.
Below is an example of an argument step where the arguments are not provided:
Incoming data to step:
Linux Debian 5.10.0-8-amd64 #1 SMP Debian 5.10.46-4 (2021-08-03) x86_64 GNU/Linux
Output without a provided argument appears as:
Linux Debian 5.10.0-8-amd64 #1 SMP Debian 5.10.46-4 (2021-08-03) x86_64 GNU/Linux
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_line
Below are two examples of a split_argument that successfully returns a dictionary where each line is an element.
Incoming data to step:
5.10.0-8-amd64
Provided input to step:
key: kernel
Output appears as:
{"kernel": "5.10.0-8-amd64"}The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_line: key: kernel
Incoming data to step:
"Tue Oct 21 17:26:30 EDT 2021"
Provided input to step:
split_type: '' key: date
Output appears as:
{"date": "Tue Oct 5 17:26:30 EDT 2021"}
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_line: split_type: '' key: date
Incoming data to step:
MemTotal: 8144576 kB MemFree: 1316468 kB MemAvailable: 3685676 kB Buffers: 403324 kB Cached: 2095104 kB SwapCached: 0 kB Active: 4581348 kB Inactive: 1156620 kB Active(anon): 3254544 kB Inactive(anon): 116952 kB
Provided input to step:
split_type: colon key: from_outputOutput appears as:
{ "MemTotal": "8144576 kB", "MemFree": "1316468 kB", "MemAvailable": "3685676 kB", "Buffers": "403324 kB", "Cached": "2095104 kB", "SwapCached": "0 kB", "Active": "4581348 kB", "Inactive": "1156620 kB", "Active(anon)": "3254544 kB", "Inactive(anon)": "116952 kB" }
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_line: split_type: colon key: from_output
Parse Proc/net/snmp¶
The Parse Proc/net/snmp turns the output of a proc, net or snmp
command into an addressable data dictionary. The generated dictionary
contains the keys of one line and the values of the consecutive lines.
Step details:
Framework Name |
|
Incoming data type |
string or list of strings |
Return data type |
dictionary |
Below is an example of a Parse Proc/net/snmp step.
Incoming data to step:
Ip: Forwarding DefaultTTL InReceives InHdrErrors InAddrErrors ForwDatagrams Ip: 2 64 2124746 0 61 0 Icmp: InMsgs InErrors InCsumErrors InDestUnreachs InTimeExcds InParmProbs InSrcQuenchs InRedirects Icmp: 7474 0 0 98 0 0 0 0 IcmpMsg: InType3 InType8 OutType0 OutType3 IcmpMsg: 98 7376 7376 104 Tcp: RtoAlgorithm RtoMin RtoMax MaxConn ActiveOpens PassiveOpens AttemptFails EstabResets Tcp: 1 200 120000 -1 2760 13547 55 597 Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti Udp: 87737 104 0 10695 0 0 0 405592 UdpLite: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors UdpLite: 0 0 0 0 0 0 0
Output:
{ "Ip": { "Forwarding": 2, "DefaultTTL": 64, "InReceives": 2124746, "InHdrErrors": 0, "InAddrErrors": 61, "ForwDatagrams": 0, }, "Icmp": { "InMsgs": 7474, "InErrors": 0, "InCsumErrors": 0, "InDestUnreachs": 98, "InTimeExcds": 0, "InParmProbs": 0, "InSrcQuenchs": 0, "InRedirects": 0, }, "IcmpMsg": { "InType3": 98, "InType8": 7376, "OutType0": 7376, "OutType3": 104 }, "Tcp": { "RtoAlgorithm": 1, "RtoMin": 200, "RtoMax": 120000, "MaxConn": -1, "ActiveOpens": 2760, "PassiveOpens": 13547, "AttemptFails": 55, "EstabResets": 597, }, "Udp": { "InDatagrams": 87737, "NoPorts": 104, "InErrors": 0, "OutDatagrams": 10695, "RcvbufErrors": 0, "SndbufErrors": 0, "InCsumErrors": 0, "IgnoredMulti": 405592, }, "UdpLite": { "InDatagrams": 0, "NoPorts": 0, "InErrors": 0, "OutDatagrams": 0, "RcvbufErrors": 0, "SndbufErrors": 0, "InCsumErrors": 0, }, }
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_proc_net_snmp
Parse Split Response¶
Parse Split Responses convert multi-line Unix output, from a command, to a list of a strings. Each line of the Unix command response will appear as an element of the returned list in the step’s output.
Step details:
Step |
|
Incoming data type |
string |
Return data type |
list of strings |
Below are two examples of a parse split response step.
Incoming data to step:
nr_free_pages 359986 nr_zone_inactive_anon 29307 nr_zone_active_anon 769830 nr_zone_inactive_file 251253 nr_zone_active_file 356384
Output:
[ "nr_free_pages 359986", "nr_zone_inactive_anon 29307", "nr_zone_active_anon 769830", "nr_zone_inactive_file 251253", "nr_zone_active_file 356384" ]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_split_response
Incoming data to step:
Some SSH response
Output:
["Some", "SSH", "response"]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_split_response
Regex¶
The Regex step uses regular expressions to extract the required information and returns a dictionary.
Step details:
Framework Name |
|
Parameters |
|
Reference |
Example Usage¶
If the incoming data to the step is:
"some text where the regex will be applied"
If we wanted to provide these input parameters:
flags: "I","M"
method: search
regex: "(.*)"
The output of this step will be:
{
"match": "some text where the regex will be applied",
"groups": ("some text where the regex will be applied",),
"span": (0, 41)
}
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- regex_parser
flags:
- I
- M
method: search
regex: "(.*)"
String Float¶
The String Float parses a string to float. If the string contains multiple floats, it returns a list of them.
Framework Name |
|
Example Usage¶
If the incoming data to the step is:
"1.1 , 2.2"
The output of this step will be:
[1.1, 2.2]
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- stringfloat
Data Table Parsers¶
Parse Netstat¶
A Parse Netstat, as any of the Data Table Parsers, converts the table-like Unix command response into an addressable data dictionary.
It is common to see Unix command outputs that look like tables as in the example below.
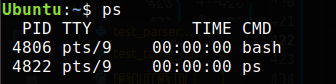
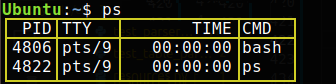
When working with this type of response, you can use a Data Table Parser that turns the Unix command response that looks like a table into an addressable data structure.
The Parse Netstat works similar to the Parse Table Row, it parses
responses from the netstat command. This provides a dedicated port
key for the Local Address in the netstat response.
Step details:
Framework Name |
|
Incoming data type |
list of strings or string |
Return data type |
dictionary |
Configuration of arguments¶
Various arguments can be configured for the Parse Netstat step. This includes:
Argument |
Type |
Default |
|---|---|---|
|
str |
single_space |
|
bool |
True |
|
bool |
True |
|
str |
“” |
|
str |
“” |
|
dict |
{} |
Below is an example of a Parse Netstat step.
Incoming data to step:
Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.1.1:53 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN tcp6 0 0 :::22 :::* LISTEN tcp6 0 0 ::1:631 :::* LISTEN
Input arguments to step:
split_type: single_space, skip_header: True, modify_headers: True, separator: "", headers: "",
Output:
{ "proto": ["tcp", "tcp", "tcp", "tcp6", "tcp6"], "recv-q": ["0", "0", "0", "0", "0"], "send-q": ["0", "0", "0", "0", "0"], "local_address": ["127.0.1.1:53", "0.0.0.0:22", "127.0.0.1:631", ":::22", "::1:631"], "foreign_address": ["0.0.0.0:*", "0.0.0.0:*", "0.0.0.0:*", ":::*", ":::*"], "state": ["LISTEN", "LISTEN", "LISTEN", "LISTEN", "LISTEN"], "port": ["53", "22", "631", "22", "631"], }
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_netstat: split_type: single_space skip_header: True modify_headers: True separator: "" headers: ""
Parse Sectional Rows¶
Parse Sectional Row parsers convert the table format response to a data dictionary. For each line, the parser exhibits the following behavior:
If no colon (:) is provided in the value, the last 12 characters will be removed. The string will then be transformed to lower-case, excluding spaces. This value will be used as a key in the output dictionary.
If a colon (:) is provided, the data to the left will be they key, and data to the right will be the value.
Step details:
Framework Name |
|
Incoming data type |
list of strings or dictionary |
Return data type |
dictionary |
Configuration of arguments¶
The following argument can be configured for the Parse Sectional Row step. This includes:
Argument |
Type |
Default |
Description |
|---|---|---|---|
key |
string |
“” |
Optional. Use this argument when the input data is a
dictionary and you need to parse an element
(example 2).
|
Below are two examples of the Parse Sectional Rows step.
Incoming data to step:
[ "Section1 Information", "1.0: First", "1.1: Second", "Section2 Information", "2.0: First", "2.1: Second", ]
If no arguments are provided, the output would be:
{ "section1": {"1.0": "First", "1.1": "Second"}, "section2": {"2.0": "First", "2.1": "Second"}, }The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_sectional_rows
Incoming data to step:
{ "data" : [ "Section1 Information", "1.0: First", "1.1: Second", "Section2 Information", "2.0: First", "2.1: Second", ] }
Input arguments to step:
key: data
Output:
{ "section1": {"1.0": "First", "1.1": "Second"}, "section2": {"2.0": "First", "2.1": "Second"}, }
The Snippet Argument appears as:
.. code-block:: yaml
:emphasize-lines: 6,7
low_code:
id: my_request
version: 2
steps:
- <network_request>
- parse_sectional_rows:
key: data
Parse Table Column¶
The Parse Table Column step turns the Unix command response into a list of addressable dictionaries. Each dictionary corresponds to a single line of the command response. Users also have the option to skip lines.
Step details:
Framework Name |
|
Incoming data type |
strings or list of strings |
Return data type |
list of dictionaries |
Return data type |
list of dictionaries |
Configuration of arguments¶
Various arguments are available for configuration in this step. These include:
Argument |
Type |
Default |
Description |
|---|---|---|---|
|
int |
0 |
Optional. Useful for skipping lines that should not be
included as input for parsing. It represents the number
of skipped lines at the beginning.
|
|
int |
0 |
Optional. Useful for skipping lines that should not be
included as input for parsing. It represents the number
of skipped lines at the end.
|
|
list |
None |
|
|
int |
None |
Required. This argument is the maximum number of
columns the parser should use when parsing the input
data. It needs to be equal to or greater than the number
of actual columns in the command response. The column
count starts at 0 (e.g. if you have 5 columns, your max
would be 4). It’s helpful if the table response has extra
white spaces (which will be interpreted as empty columns)
at the end.
|
Below are three examples of the Parse Table Column step.
Incoming data to step:
total 36 -rw------- 1 em7admin em7admin 2706 Oct 21 19:00 nohup.out -rw-r--r-- 1 em7admin em7admin 32 Nov 3 17:35 requirements.txt
Input arguments to step:
skip_lines_start: 1 skip_lines_end: 0 columns: 8
Output:
[ { 0: "-rw-------", 1: "1", 2: "em7admin", 3: "em7admin", 4: "2706", 5: "Oct", 6: "21", 7: "19:00", 8: "nohup.out", }, { 0: "-rw-r--r--", 1: "1", 2: "em7admin", 3: "em7admin", 4: "32", 5: "Nov", 6: "3", 7: "17:35", 8: "requirements.txt", }, ]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_table_column: skip_lines_start: 1 skip_lines_end: 0 columns: 8
Incoming data to step:
Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.1.1:53 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN tcp6 0 0 :::22 :::* LISTEN tcp6 0 0 ::1:631 :::* LISTEN
Input arguments to step:
skip_lines_start: 2 skip_lines_end: 1 columns: 5
Output:
[ {0: "tcp", 1: "0", 2: "0", 3: "127.0.1.1:53", 4: "0.0.0.0:*", 5: "LISTEN"}, {0: "tcp", 1: "0", 2: "0", 3: "0.0.0.0:22", 4: "0.0.0.0:*", 5: "LISTEN"}, {0: "tcp", 1: "0", 2: "0", 3: "127.0.0.1:631", 4: "0.0.0.0:*", 5: "LISTEN"}, {0: "tcp6", 1: "0", 2: "0", 3: ":::22", 4: ":::*", 5: "LISTEN"}, {0: "tcp6", 1: "0", 2: "0", 3: "::1:631", 4: ":::*", 5: "LISTEN"}, ]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_table_column: skip_lines_start: 2 skip_lines_end: 1 columns: 8
Incoming data to step:
Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.1.1:53 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN tcp6 0 0 ::1:631 :::* LISTEN
Input arguments to step:
skip_lines_start: 2 skip_lines_end: 0 key_list : ["protocol", "recv-q", "send-q", "local", "foreign", "state"] columns: 5
Output:
[ {'protocol': 'tcp', 'recv-q': '0', 'send-q': '0', 'local': '127.0.1.1:53', 'foreign': '0.0.0.0:*', 'state': 'LISTEN'}, {'protocol': 'tcp', 'recv-q': '0', 'send-q': '0', 'local': '127.0.0.1:631', 'foreign': '0.0.0.0:*', 'state': 'LISTEN'}, {'protocol': 'tcp6', 'recv-q': '0', 'send-q': '0', 'local': '::1:631', 'foreign': ':::*', 'state': 'LISTEN'} ]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_table_column: skip_lines_start: 2 skip_lines_end: 0 key_list: - protocol - recv-q - send-q - local - foreign - state columns: 5
Parse Table Row¶
A Parse Table Row converts the table-like Unix command response into an addressable data dictionary.
Step details:
Step |
|
Incoming data type |
strings or list of strings |
Return data type |
dictionary |
Configuration of arguments¶
Many arguments can be configured for the Parse Table Row step. This includes:
Argument |
Type |
Default |
Description |
|---|---|---|---|
|
str |
single_space |
Optional. This argument determines the split type.
For this particular step, the valid options are
(more details):
- single_space
- without_header
- custom_space
|
|
bool |
False |
Optional. This argument defines if the parser
needs to skip the first line of the command
response, a line that is not meaningful for the
parsing (netstat example 1).
|
|
bool |
True |
Optional. This argument determines if the parser
needs to modify the header names or not. Values
for the change need to be provided in the
headers_to_replace argument. The following valueschange by default if they exist in the command
response and the argument is set to True,
even if you do not provide the
headers_to_replaceargument (example 2 and netstat example 1):
- Mounted on will be replaced by mounted_on
- IP address will be replaced by ip_address
- HW type will be replaced by hw_type
- HW address will be replaced by hw_address
- Local Address will be replaced by local_address
- Foreign Address will be replaced by foreign_address
|
|
str |
“ “ |
Optional. This argument sets the string that will be
used to split the command output when the
split_type is set to custom_space. |
|
str |
“” |
Optional. To be used when
split_type parameteris set to without_header so that you can apply your
own set headers to the table command response. It
works with
split_type argument set towithout_header. It needs to be a string of keys
determined by a space delimiter.
|
|
dict |
{} |
Optional. Use this argument when
modify_headersis set to True. Uses the dictionary argument
provided, where the keys are the current header
names of the response and the values are the new
header names you want to replace the current ones
with.
|
The
split_typeargument can take any of the following values:
single_space - It will parse the table formatted command output into a dictionary by converting the first row/line of data into the keys of the dictionary and the value for each key is a list of all the column line items under the key/header (see example 1 and example 2). The parser transforms the keys into lower case. Acknowledge that the spaces in the header line define the keys; a single space character is enough to consider the following value as a different key. For this reason, it is necessary to replace values of the header line and remove the space by using the
modify_headersandheaders_to_replacearguments.without_header - Works like single_space but should be used when the table formatted command output does not have a header row. This provides an opportunity for you to apply your own headers with the
headersargument.custom_space - Turns each line of the table into an element of the dictionary. The first item of each line in the command output is used as the key, and the remaining items in the row are set into a list (example 4).
Below are four examples of the Parse Table Row step.
Incoming data to step:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND user1 6458 0.0 0.0 15444 924 pts/5 S+ 15:14 0:00 grep --color=auto Z
Input arguments to step:
split_type: single_space, skip_header: False, modify_headers: False, separator: "", headers: "",
Output:
{ "user": ["user1"], "pid": ["6458"], "%cpu": ["0.0"], "%mem": ["0.0"], "vsz": ["15444"], "rss": ["924"], "tty": ["pts/5"], "stat": ["S+"], "start": ["15:14"], "time": ["0:00"], "command": ["grep --color=auto Z"], }
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_table_row: split_type: single_space skip_header: False modify_headers: False separator: "" headers: ""
Incoming data to step:
Filesystem Type 1024-blocks Used Available Capacity Mounted on udev devtmpfs 3032744 0 3032744 0% /dev tmpfs tmpfs 611056 62508 548548 11% /run /dev/sda1 ext4 148494760 7255552 133673080 6% / tmpfs tmpfs 3055272 244 3055028 1% /dev/shm tmpfs tmpfs 5120 0 5120 0% /run/lock tmpfs tmpfs 3055272 0 3055272 0% /sys/fs/cgroup tmpfs tmpfs 611056 84 610972 1% /run/user/1000
Input arguments to step:
split_type: single_space, skip_header: False, modify_headers: True, separator: "", headers: "",
Output:
{ "filesystem": ["udev", "tmpfs", "/dev/sda1", "tmpfs", "tmpfs", "tmpfs", "tmpfs"], "type": ["devtmpfs", "tmpfs", "ext4", "tmpfs", "tmpfs", "tmpfs", "tmpfs"], "1024-blocks": ["3032744", "611056", "148494760", "3055272", "5120", "3055272", "611056"], "used": ["0", "62508", "7255552", "244", "0", "0", "84"], "available": ["3032744", "548548", "133673080", "3055028", "5120", "3055272", "610972"], "capacity": ["0%", "11%", "6%", "1%", "0%", "0%", "1%"], "mounted_on": [ "/dev", "/run", "/", "/dev/shm", "/run/lock", "/sys/fs/cgroup", "/run/user/1000", ], }
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_table_row: split_type: single_space skip_header: False modify_headers: True separator: "" headers: ""
Incoming data to step:
2 0 fd0 0 0 0 0 0 0 0 0 0 0 0 8 0 sda 530807 21 8777975 687626 13983371 161787 551438764 48053137 0 21892797 48721313 8 1 sda1 1804 0 11227 721 2049 0 4096 2906 0 3620 3626 8 2 sda2 528973 21 8764652 686683 13981322 161787 551434668 48050231 0 21890022 48728814 11 0 sr0 0 0 0 0 0 0 0 0 0 0 0 253 0 dm-0 16049 0 848912 45328 117397 0 714586 627210 0 387658 673185 253 1 dm-1 94 0 4456 35 0 0 0 0 0 25 35 253 2 dm-2 110 0 10380 337 406452 0 4416366 1593673 0 1530349 1594671 253 3 dm-3 191 0 14017 410 399562 0 3725067 1657647 0 1063574 1689139 253 4 dm-4 6125 0 167987 10596 2209975 0 65264306 7899194 0 2173858 7956596 253 5 dm-5 163 0 7111 661 926632 0 9161743 2889610 0 2705664 2892645 253 6 dm-6 143 0 2475 400 257 0 5509 708 0 996 1108 253 7 dm-7 505998 0 7706482 629324 10082835 0 468147091 34574715 0 14668657 35212163
Input arguments to step:
split_type: without_header, skip_header: False, modify_headers: False, separator: "", headers: "major_number minor_mumber device_name reads_completed_successfully reads_merged sectors_read time_spent_reading(ms) writes_completed writes_merged sectors_written time_spent_writing(ms) I/Os_currently_in_progress time_spent_doing_I/Os(ms) weighted_time_spent_doing_I/Os(ms)
Output:
{ "major_number": [ "2", "8", "8", "8", "11", "253", "253", "253", "253", "253", "253", "253", "253",], "minor_mumber": ["0", "0", "1", "2", "0", "0", "1", "2", "3", "4", "5", "6", "7"], "device_name": ["fd0", "sda", "sda1", "sda2", "sr0", "dm-0", "dm-1", "dm-2", "dm-3", "dm-4", "dm-5", "dm-6", "dm-7",], "reads_completed_successfully": ["0", "530807", "1804", "528973", "0", "16049", "94", "110", "191", "6125", "163", "143", "505998",], "reads_merged": ["0", "21", "0", "21", "0", "0", "0", "0", "0", "0", "0", "0", "0"], "sectors_read": ["0", "8777975", "11227", "8764652", "0", "848912", "4456", "10380", "14017", "167987", "7111", "2475", "7706482", ], "time_spent_reading(ms)": [ "0", "687626", "721", "686683", "0", "45328", "35", "337", "410", "10596", "661", "400", "629324", ], "writes_completed": [ "0", "13983371", "2049", "13981322", "0", "117397", "0", "406452", "399562", "2209975", "926632", "257", "10082835", ], "writes_merged": ["0", "161787", "0", "161787", "0", "0", "0", "0", "0", "0", "0", "0", "0"], "sectors_written": [ "0", "551438764", "4096", "551434668", "0", "714586", "0", "4416366", "3725067", "65264306", "9161743", "5509", "468147091", ], "time_spent_writing(ms)": ["0", "48053137", "2906", "48050231", "0", "627210", "0", "1593673", "1657647", "7899194", "2889610", "708", "34574715",], "I/Os_currently_in_progress": ["0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", ], "time_spent_doing_I/Os(ms)": ["0", "21892797", "3620", "21890022", "0", "387658", "25", "1530349", "1063574", "2173858", "2705664", "996", "14668657",], "weighted_time_spent_doing_I/Os(ms)": [ "0", "48721313", "3626", "48728814", "0", "673185", "35", "1594671", "1689139", "7956596", "2892645", "1108", "35212163",], }
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_table_row: split_type: without_header skip_header: False modify_headers: False separator: "" headers: "major_number minor_mumber device_name reads_completed_successfully reads_merged sectors_read time_spent_reading(ms) writes_completed writes_merged sectors_written time_spent_writing(ms) I/Os_currently_in_progress time_spent_doing_I/Os(ms) weighted_time_spent_doing_I/Os(ms)"
Incoming data to step:
cpu 55873781 59563877 9860209 722670590 35449 0 78511 0 0 0 cpu0 27983218 29082019 4926645 361957968 20859 0 24137 0 0 0 cpu1 27890563 30481858 4933564 360712621 14590 0 54374 0 0 0 intr 2141799923 22 257 0 0 0 0 0 0 1 0 0 0 15861 0 0 0 61 191591 ctxt 5821097301 btime 1571712300 processes 217415 procs_running 2 procs_blocked 0 softirq 888390539 0 370421671 854059 3231656 2258408 0 499710 374437477 0 136687558
Input arguments to step:
split_type: custom_space, skip_header: False, modify_headers: False, separator: " ", headers: "",
Output:
{ "cpu": ["55873781", "59563877", "9860209", "722670590", "35449", "0", "78511", "0", "0", "0"], "cpu0": ["27983218", "29082019", "4926645", "361957968", "20859", "0", "24137", "0", "0", "0",], "cpu1": ["27890563", "30481858", "4933564", "360712621", "14590", "0", "54374", "0", "0", "0",], "intr": ["2141799923", "22", "257", "0", "0", "0", "0", "0", "0", "1", "0", "0", "0", "15861", "0", "0", "0", "61", "191591",], "ctxt": ["5821097301"], "btime": ["1571712300"], "processes": ["217415"], "procs_running": ["2"], "procs_blocked": ["0"], "softirq": [ "888390539", "0", "370421671", "854059", "3231656", "2258408", "0", "499710", "374437477", "0", "136687558",], }
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - parse_table_row: split_type: custom_space skip_header: False modify_headers: False separator: "" headers: ""
Formatters¶
Format Build String¶
The Format Build String step formats strings for lists of related values. The input data is a dictionary of value lists, and the output is the list of strings. The input dictionary is represented as a table with keys shown in columns, and the list items shown in the cells. The output is a list of strings with each string shown as a row in the table.
The Format Build String step is used when receiving a table’s data that provides a composite output for a collection object. For example, a process listing’s process name and process arguments are located in different fields; meaning, both fields can be combined into a single collection object that shows the executed command.
Step details:
Step |
|
Incoming data type |
dictionary |
Return data type |
list of strings |
Configuration of arguments¶
The following argument can be configured for the Format Build String step:
Argument |
Type |
Default |
Description |
|---|---|---|---|
keys_to_replace |
str |
Required. This argument will set the expected format to the
result. Provide the keys surrounded by curly brackets
{}and extra text if needed.
|
Below are three examples of the Format Build String step.
Incoming data to step:
{ "title": ["Mr.", "Ms."], "name": ["Joe", "Leah"], "year": [1999, 2018], "color": ["red", "blue"], }
Input arguments to step:
keys_to_replace: "{title}"
Output:
["Mr.", "Ms."]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - format_build_string: keys_to_replace: "{title}"
Incoming data to step:
{ "title": ["Mr.", "Ms."], "name": ["Joe", "Leah"], "year": [1999, 2018], "color": ["red", "blue"], }
Input arguments to step:
keys_to_replace: "{title} {name}"
Output:
["Mr. Joe", "Ms. Leah"]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - format_build_string: keys_to_replace: "{title} {name}"
Incoming data to step:
{ "title": ["Mr.", "Ms."], "name": ["Joe", "Leah"], "year": [1999, 2018], "color": ["red", "blue"], }
Input arguments to step:
keys_to_replace: "{name} {color} - since {year}"
Output:
["Joe red - since 1999", "Leah blue - since 2018"]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - format_build_string: keys_to_replace: "{name} {color} - since {year}"
Format Remove Unit¶
The Formatter Remove Unit step removes units from strings. The incoming string data must be formed by a value and a unit, in that order, and separated by a white space character.
Step details:
Step |
|
Incoming data type |
string or list of strings |
Return data type |
string or list of strings |
Below are three examples of the Format Remove Unit step. In all of the following examples, the Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- format_remove_unit
Incoming data to step:
8192 KB
Output:
8192
Incoming data to step:
["12346", "kb"]
Output:
12346
Incoming data to step:
["12345 kb", "7890 kb"]
Output:
["12345", "7890"]
Selectors¶
JMESPath¶
JMESPath is a query language for JSON data. The JMESPath step can be used on data after being JSON parsed. It uses a path expression as a parameter to specify the location of the desired element (or a set of elements). Paths use the dot notation.
The JMESPath step accepts one path expression. Additionally, the JMESPath step provides a capability to build custom indexable output. This requires the expression path to be a multiselect hash with defined _index and _value keys. See below for more information.
Step details:
Framework Name |
|
Parameters |
|
Reference |
Example Usage¶
If the incoming data to the step is:
{
"data":
[
{
"id": 1,
"name": "item1",
"children": {
"cname": "myname1"
}
},
{
"id": 2,
"name": "item2",
"children": {
"cname": "myname2"
}
}
]
}
If we provide the following input parameters:
index: true
value: "data[].{_index: id, _value: children.cname}"
The output of this step will be:
[(1, 'myname1'), (2, 'myname2')]
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- json
- jmespath:
index: true
value: "data[].{_index: id, _value: children.cname}"
If we provide the following input parameters:
index: false
value: "data[].children.cname"
The output of this step will be:
["myname1","myname2"]
The Snippet Argument should look like this:
low_code:
id: my_request2
version: 2
steps:
- <network_request>
- json
- jmespath:
value: "data[].children.cname"
JSONPath¶
The JSONPath is a query language for JSON data. The JSONPath selector can be used on any data once it has been parsed. It uses path expressions as parameters to specify a path to the element (or a set of elements). Paths use the dot notation.
The JSONPath parser can accept one or two paths. If one is given, that is the path to the data. If two are given, that provides the path to the index and the path to the data.
Step details:
Framework Name |
|
Parameters |
|
Reference |
Example Usage¶
If the incoming data to the step is:
{
"data":
[
{
"id": 1,
"name": "item1",
"children": {
"cname": "myname1"
}
},
{
"id": 2,
"name": "item2",
"children": {
"cname": "myname2"
}
}
]
}
If we wanted to provide these input parameters:
value: "$.data[*].children.cname"
index: "$.data[*].id"
The output of this step will be:
[(1, 'myname1'), (2, 'myname2')]
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- jsonpath:
value: "$.data[*].children.cname"
index: "$.data[*].id
Regex Select Table¶
The Regex Select Table step picks data by using a regular expression. Another argument, an index, can be provided. The index allows users to return more specific data.
Step details:
Step |
|
Incoming data type |
dictionary |
Return data type |
dictionary |
Configuration of arguments¶
Two arguments can be configured for the Regex Select Table step:
Argument |
Type |
Default |
Description |
|---|---|---|---|
regex |
string |
Required. This argument is the regular expression used
to parse the data.
|
|
index |
int |
None |
Optional. Use this argument to get a specific indexed value.
|
Below are three examples of the Regex Select Table step.
Incoming data to step:
{ "cpu": ["170286", "1547", "212678", "10012284"], "cpu0": ["45640", "322", "54491", "2494773"], "cpu1": ["39311", "966", "51604", "2507064"], "ctxt": ["37326362"], "btime": ["1632486419"], "processes": ["8786"], }
Input arguments to step:
regex: btime
Output:
{"btime": "1632486419"}
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - regex_select_table: regex: btime
Incoming data to step:
{ "cpu": ["170286", "1547", "212678", "10012284"], "cpu0": ["45640", "322", "54491", "2494773"], "cpu1": ["39311", "966", "51604", "2507064"], "ctxt": ["37326362"], "btime": ["1632486419"], "processes": ["8786"], }
Input arguments to step:
regex: ^cpu\d*$
Output:
{ "cpu": ["170286", "1547", "212678", "10012284"], "cpu0": ["45640", "322", "54491", "2494773"], "cpu1": ["39311", "966", "51604", "2507064"] }
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - regex_select_table: regex: ^cpu\d*$
Incoming data to step:
{ "cpu": ["170286", "1547", "212678", "10012284"], "cpu0": ["45640", "322", "54491", "2494773"], "cpu1": ["39311", "966", "51604", "2507064"], "ctxt": ["37326362"], "btime": ["1632486419"], "processes": ["8786"], }
Input arguments to step:
regex: ^cpu\d*$ index: 2
Output:
{"cpu": "212678", "cpu0": "54491", "cpu1": "51604"}
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - regex_select_table: regex: ^cpu\d*$ index: 2
Select Table Item¶
The Select Table Item step selects data using the indexes in an incoming list of dictionaries. The dictionary list is represented in a table. When an index argument is provided, the corresponding value will be returned. However, when the index argument is a list, it will concatenate the values at each index and return a single value.
Step details:
Step |
|
Incoming data type |
list of dictionaries |
Return data type |
list |
Configuration of arguments¶
The following argument can be configured for the Select Table Item step:
Argument |
Type |
Description |
|---|---|---|
index |
int or list |
Required. If the argument is an int, it works as an index
to select the data. If the argument is a list, it joins the
values at each index and returns a single value.
|
Below are four examples of the Select Table Item step.
Incoming data to step:
[{1: "2.63", 2: "8.05"}]
Input arguments to step:
index: 1
Output:
["2.63"]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - select_table_item: index: 1
Incoming data to step:
[{1: "2.63", 2: "8.05"}]
Input arguments to step:
index: [1, 2]
Output:
["2.63 8.05"]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - select_table_item: index: - 1 - 2
Incoming data to step:
[{1: "2.63", 2: "8.05"}, {1: "1.85", 2: "1.95"}]
Input arguments to step:
index: [1]
Output:
["2.63 1.85"]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - select_table_item: index: - 1
Incoming data to step:
[{0: "0.5", 1: "2.63", 2: "8.05"}, {0: "0.4", 1: "1.85", 2: "1.95"}]
Input arguments to step:
index: [0, 2]
Output:
["0.5 8.05", "0.4 1.95"]
The Snippet Argument appears as:
low_code: id: my_request version: 2 steps: - <network_request> - select_table_item: index: - 0 - 2
Simple Key¶
The Simple Key selector is for dictionaries, lists, etc. It returns the specified key by using periods as separators.
Step details:
Framework Name |
|
Format |
path.to.value |
Example Usage¶
If the incoming data to the step is:
{
"key": {
"subkey": {
"subsubkey": "subsubvalue",
"num": 12
}
}
}
If we wanted to provide these input parameters:
"key.subkey.num"
The output of this step will be:
12
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- simple_key: "key.subkey.num"
If the incoming data to the step is:
{
"key": {
1: {
"2": ["value0", "value1", "value2"]
}
}
}
If we wanted to provide these input parameters:
"key.1.2.0"
The output of this step will be:
"value0"
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- simple_key: "key.1.2.0"
If the incoming data to the step is:
[
{"id": "value0"},
{"id": "value1"}
]
If we wanted to provide these input parameters:
"id"
The output of this step will be:
["value0", "value1"]
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- simple_key: "id"
Ungrouped¶
Store Data¶
The store_data step allows a user to store the current result into a key of their choosing. This enables a pre-processed dataset to be used at a later time where it may be necessary to have the full result. An example of this could be trimming data you do not need but requiring the whole payload to make a decision in the future.
This step does not update request_id so it will not affect the automatic cache_key generated by the Snippet Framework.
Framework Name |
|
key |
storage_key |
For example, if you wanted to store the current result into
the key storage_key, you would use the following step
definition:
store_data: storage_key
To access this data in a later step, you would use the following:
result_container.metadata["storage_key"]
Cachers¶
cache_writer¶
The cache_writer step enables user defined caching (read and write) to Skylar One's DB instance.
Step details:
Framework Name |
|
|
Parameters |
key: |
Metadata key that the DB will use for cache R/W (default: request_id) |
reuse_for: |
Time in minutes that specifies valid cache entry duration times to be Read. (default: 5) |
|
cleanup_after: |
Time in minutes that specifies when caches will expire and should be removed from the DB (default: 15) |
|
Note
When the parameter reuse_for is defined as 0 minutes, the cache_writer
will not allow a fast-forward in the pipeline execution.
Note
When the parameter cleanup_after is defined to be smaller than
reuse_for, the cache_writer will fail to find valid data and run
through the step execution up to the point of cache_writer.
Example Usage¶
Below is an example where we want to make a network request, process the data (json->dict) and then select a subset of that data.
The Snippet Argument should look like this:
low_code:
id: my_request
version: 2
steps:
- <network_request>
- json
- simple_key: "id"
Let’s assume that the network request and json processing are steps that we would like to cache
and possibly reuse in another collection and/or dynamic application. I am going use a custom key,
here with a cache reuse time, reuse_for, of 5 minutes and a clean up, cleanup_after on
my cache entries after 15 minutes.
low_code:
id: my_request
version: 2
steps:
- <network_request>
- json
- cache_writer:
key: here
reuse_for: 5
cleanup_after: 15
- simple_key: "id"
It there is a cache entry that is 5 minutes or newer since the start of the collection cycle the step will
read the cached value and fast forward to the simple_key step.