![]()
Machine learning-based anomaly detection is available only in SL1 Premium solutions. To upgrade, contact ScienceLogic Customer Support.
To use machine learning-based anomaly detection, you must be running SL1 on the SL1 Extended Architecture, and you must also enable the Collector Pipeline to collect data from Performance Dynamic Applications. For more information, see
Use the following menu options to navigate the SL1 user interface:
- To view a pop-out list of menu options, click the menu icon (
 ).
). - To view a page containing all the menu options, click the Advanced menu icon (
 ).
).
The following video explains machine learning-based anomaly detection and Business Services:
What is Anomaly Detection?
Anomaly detection is a technique that uses machine learning to identify unusual patterns that do not conform to expected behavior. SL1 does this by collecting data for a particular metric over a period of time, learning the patterns of that particular device metric, and then choosing the best possible algorithm to analyze that data.
SL1 uses the resulting combination of collected data and the auto-selected algorithm to build a model that is unique to that specific device and metric. That model is then used to anticipate the expected behavior for that device metric. Anomalies are detected when the actual collected data value falls outside the boundaries of the expected value range.
SL1 then continuously refines the model as it collects more data.
Anomalies do not necessarily represent problems or events to be concerned about; rather, they represent unexpected behavior that you might want to investigate.
Anomaly Detection Terminology
The following are some terms that are used when discussing machine learning-based anomaly detection, and their definitions.
- Algorithm. A mathematical formula for data analysis. SL1 currently uses period-based and multiple clustering algorithms to perform anomaly detection, with the ability to easily add more algorithms in the future.
- Model. The combination of collected data and algorithm that SL1 uses to anticipate expected behavior and discover anomalies for a specific metric on a specific device. SL1 constantly refines these models.
- Model Selector. An automatic model selector included in SL1 that examines the historical data for the selected metric and ensures there is enough data for successful analysis, applies all possible algorithms to the data, then determines the algorithm that is best able to distinguish anomalies in the data in order to build the model for the selected metric.
How is Anomaly Detection Different from Standard Deviation?
In SL1, you can use the deviation function to examine values collected by Dynamic Applications. The deviation function compares each collected value to the mean value for that hour and that day of the week. Deviation triggers an alert only when values fall outside the historical range of data, but will not trigger an alert when something abnormal happens within that range.
In contrast, anomaly detection learns the behavioral shapes and patterns of a data point and triggers an alert when values for that data point fall outside the behavioral shape. For example, anomaly detection could generate an alert when it discovers an unexpected flatline, a spike during a "low usage" period, or when collected values should repeat a pattern but do not. All these behaviors could occur within a standard deviation from the mean value so would not be discovered with the deviation function.
How Does SL1 Detect Anomalies?
The following steps describe the basic process SL1 uses to detect anomalies:
- SL1 observes the behavior of a single metric on a single device, using historical and current time-series data.
- Based on the observed behavior, SL1 performs calculations and builds a model that is specific to that single metric on that single device.
- SL1 detects behavior that is abnormal compared to the model. This abnormal behavior is considered an anomaly.
- SL1 then regularly refines its original model as more data is collected about the single metric on the single device.
- Every two weeks, SL1 will rebuild the model. This enables it to adapt to new data patterns that have emerged since the last time the model was built.
Because the anomaly detection model is constantly being refined, you might experience a greater number of anomalies after you initially enable anomaly detection than you would after it has been enabled for a longer period of time. This is simply because there is less collected data to "train" the model after anomaly detection has initially been enabled, and it will begin to better understand longer-term behavior patterns the longer it collects and analyzes data.
Anomaly detection in SL1 can examine vitals data and any performance data collected by a Dynamic Application.
When it discovers an anomaly, SL1 generates an alert. Optionally, you can choose to create events based on these alerts.
What Can Anomaly Detection Do?
After you enable machine learning-based anomaly detection for a metric on a device, SL1 requires a certain amount of historical data in order to select the model it will use to detect anomalies. Depending on the configured polling frequency and the amount of historical data that is available for the device metric, it might take SL1 under an hour or up to several days to begin detecting anomalies.
After SL1 begins performing anomaly detection for a device, you can do the following:
- You can view graphs and data about each anomaly. Graphs for anomalies appear on the following pages in SL1:
- The tab in the Device Investigator
- The Anomalies widget in the Service Investigator for a business, IT, or device service
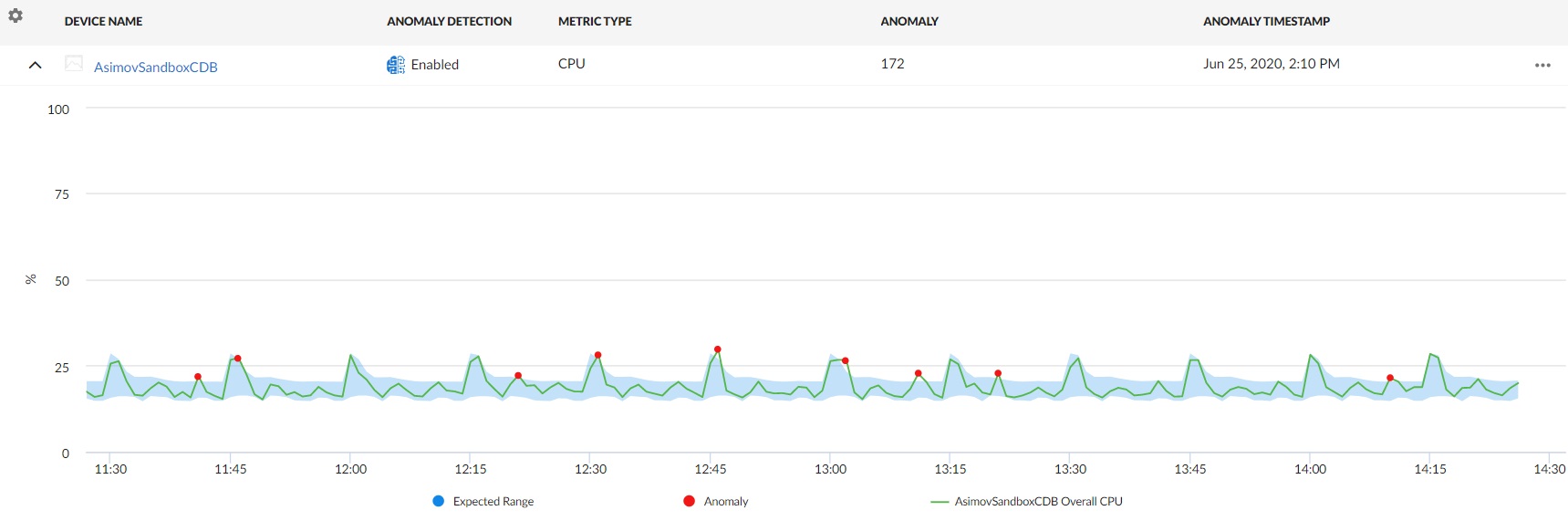
In the graph below, the blue shape represents the expected CPU value range for the selected device over the given time period, the green line indicates the actual CPU values that SL1 collected over that time period, and the red dots represent the anomalies where the actual CPU value fell outside of the expected range.
- You can use anomaly detection to trigger an event or to add extra criteria to an event policy. For example, you could specify that if an anomaly occurs five times within 10 minutes, SL1 should trigger an event.
- You can also use events based on anomaly detection to trigger Run Book Automation actions that perform further diagnostics or send notifications.
Because anomalies do not always correspond to problems, ScienceLogic recommends creating an event policy only for scenarios where anomalies appear to be correlated with some other behavior that you cannot otherwise track using an event or alert.