![]()
SL1 has multiple options for backup, recovery, and high availability. Different appliance configurations support different options; your backup, recovery, and high availability requirements will guide the configuration of your SL1 System.
This table summarizes which of the options listed in this chapter are supported by:
- All-In-One Appliances
- Distributed systems that do not use a SAN (Storage Area Network) for storage
- Distributed systems that use a SAN (Storage Area Network) for storage
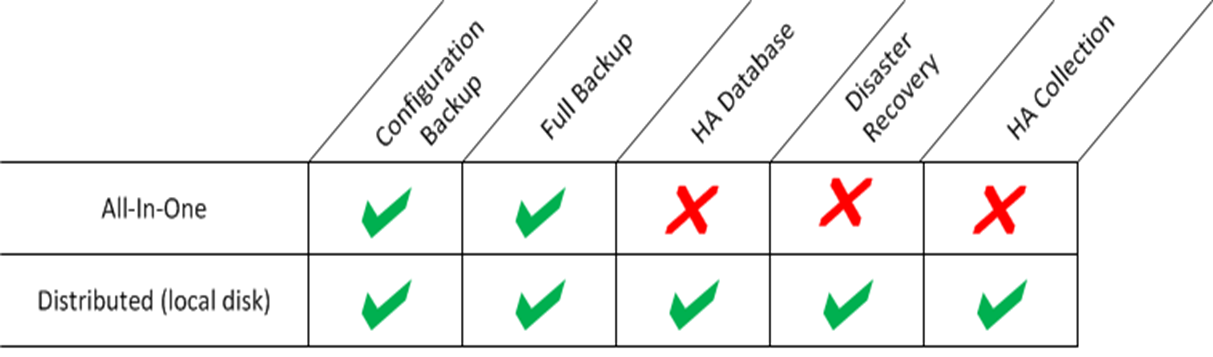
This
Configuration Backups
SL1 allows you to configure a scheduled backup of all configuration data stored in the primary database. Configuration data includes scope and policy information, but does not include collected data, events, or logs.
SL1 can perform daily configuration backups while the database is running and does not suspend any ScienceLogic services.
SL1 can save local copies of the last seven days of configuration backups and stores the first configuration backup of the month for the current month and the first configuration backup of the month for the three previous months. Optionally, you can configure SL1 to either copy the daily configuration backup to an external file system using FTP, SFTP, NFS, or SMB or write the daily configuration backup directly to an external file system.
All configurations of SL1 support configuration backups.
The configuration backup process automatically ensures that the backup media is large enough. The configuration backup process calculates the sum of the size of all the tables to be backed up and then doubles that size; the resulting number is the required disk space for configuration backups. In almost all cases, the required space is less than 1 GB.
Scheduled Backups to External File Systems
Running a full backup creates a complete backup of the ScienceLogic database. Full backups use a built-in tool call MariaBackup.
You must store full backups on an external system (not the Database Server or All-In-One Appliance). You can specify that full backups be stored on
SL1 Systems prior to 8.12 allow you to store backups locally. New SL1 systems later than 8.12 require you to store backups on an external system.
If you have a large system and very large backup files, you can use an alternative method to perform backups that reduces performance issues during backup. For more information, see Performing Config Backups and Full Backups on a Disaster Recovery Database Server.
Note the following information about full backups:
- SL1 can launch full backups automatically at the interval you specify.
- During a full backup, the ScienceLogic database remains online.
Backup of Disaster Recovery Database
For SL1 systems configured for disaster recovery, you can backup the secondary Disaster Recovery database instead of backing up the primary Database Server. This backup option temporarily stops replication between the databases, performs a full backup of the secondary database, and then re-enables replication and performs a partial re-sync from the primary.
ScienceLogic recommends that you backup to an external file system when performing a DR backup.
- DR backup includes all configuration data, performance data, and log data.
- During DR backup, the primary Database Server remains online.
- DR backup is disabled by default. You can configure SL1 to automatically launch this backup at a frequency and time you specify.
- The backup is stored on an NFS mount or SMB mount.
NOTE: The DR Backup fields appear only for systems configured for Disaster Recovery. DR Backup is not available for the two-node High Availability cluster.
Database Replication for Disaster Recovery
You can configure SL1 to replicate data stored on a Database Server to a Disaster Recovery appliance with the same specifications. You can install the Disaster Recovery appliance at the same site as the primary Database Server (although this is not recommended) or at a different location.
If the primary Database Server fails for any reason, you must manually perform failover. Failover to the Disaster recovery appliance is not automated by SL1.
High Availability for Database Servers
You can cluster Database Servers in the same location to allow for automatic failover.
A cluster includes an active Database Server and a passive Database Server. The passive Database Server provides redundancy and is dormant unless a failure occurs on the active Database Server. SL1 uses block-level replication to ensure that the data on each Database Server's primary file system is identical and that each Database Server is ready for failover if necessary. If the active Database Server fails, the passive Database Server automatically becomes active and performs all required database tasks. The previously passive Database Server remains active until another failure occurs.
Each database cluster uses a virtual IP address that is always associated with the primary Database Server. No reconfiguration of Administration Portals is required in the event of failover.
The following requirements must be met to cluster two Database Servers:
- The Database Servers must have the same hardware configuration.
- Two network paths must be configured between the two Database Servers. One of the network paths must be a direct connection between the Database Servers using a crossover cable.
NOTE: All-In-One Appliances cannot be configured in a cluster for high availability.
Differences Between Disaster Recovery and High Availability for Database Servers
SL1 provides two solutions that allow for failover to another Database Server if the primary Database Server fails: Disaster Recovery and High Availability. There are several differences between these two distinct features:
- Location. The primary and secondary databases in a High Availability configuration must be located together to configure the heartbeat network. In a Disaster Recovery configuration, the primary and secondary databases can be in different locations.
- Failover. In a High Availability configuration, SL1 performs failover automatically, although a manual failover option is available. In a Disaster Recovery configuration, failover must be performed manually.
- System Operations. A High Availability configuration maintains SL1 system operations if failure occurs on the hardware or software on the primary Database Server. A Disaster Recovery configuration maintains SL1 system operations if the data center where the primary Database Server is located has a major outage, provides a spare Database Server that can be quickly installed if the primary Database Server has a permanent hardware failure, and/or to allow for rotation of SL1 system operations between two data centers.
NOTE: A Distributed SL1 system can be configured for both High Availability and Disaster Recovery.
High Availability and Disaster Recovery are not supported for All-In-One Appliances.
High Availability for Data Collection
In a Distributed SL1 system, the Data Collectors and Message Collectors are grouped into Collector Groups. A Distributed SL1 system can include one or more Collector Groups. The Data Collectors included in a Collector Group must have the same hardware configuration.
In SL1, each monitored device is aligned with a Collector Group and SL1 automatically determines which Data Collector in that collector group is responsible for collecting data from the monitored device. SL1 evenly distributes the devices monitored by a collector group across the Data Collectors in that collector group. Each monitored device can send syslog and trap messages to any of the Message Collectors in the collector group aligned with the monitored device.
To use a Data Collector for message collection, the Data Collector must be in a collector group that contains no other Data Collectors or Message Collectors.
If you require always-available data collection, you can configure a Collector Group to include redundancy. When a Collector Group is configured for high availability (that is, to include redundancy), if one of the Data Collectors in the collector group fails, SL1 will automatically redistribute the devices from the failed Data Collector among the other Data Collectors in the Collector Group. Optionally, SL1 can automatically redistribute the devices again when the failed Data Collector is restored.
Each collector group that is configured for high availability includes a setting for Maximum Allowed Collector Outage. This setting specifies the number of Data Collectors that can fail and data collection will still continue as normal. If more Data Collectors than the specified maximum fail simultaneously, some or all monitored devices will not be monitored until the failed Data Collectors are restored.
High availability is configured per-Collector Group, so a SL1 system can have a mix of high availability and non-high availability collector groups, including non-high availability collector groups that contain a Data Collector that is also being used for message collection.
Restrictions
High availability for data collection cannot be used:
- In All-In-One Appliance systems.
- For Collector Groups that include a Data Collector that is being used for message collection.
For more information on the possible configurations for a Collector Group, see the Collector Group Configurations section.